Here is a snippet of the table I am working with:
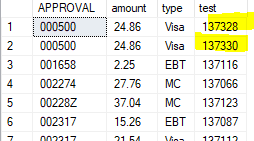
My goal is to only select one of these highlighted rows (doesn't matter which). They have duplicate approval, amount, and type columns but unique numbers in the "test" column. I would like to select all of these with the exception of one of the highlighted rows.
Any help would be greatly appreciated.
CodePudding user response:
This is a "greatest-n-per-group" problem. If you really don't care which row you get, you can use @@SPID:
;WITH cte AS
(
SELECT APPROVAL, amount, type, test,
rn = ROW_NUMBER() OVER
(
PARTITION BY APPROVAL, amount, type -- this defines grouping
ORDER BY @@SPID -- this says "I don't care what order"
)
FROM dbo.source_table
)
SELECT APPROVAL, amount, type, test
FROM cte
WHERE rn = 1;
If you care, you can add different criteria, e.g.
ORDER BY test DESC -- for the biggest value of test
Or
ORDER BY test -- for the smallest value of test
If you don't care which test you get, why does it even get returned?
CodePudding user response:
Is this what you are looking for?
SELECT DISTINCT approval, amount
FROM transactions
WHERE test not in (137328,137330);