I'm trying to read this website 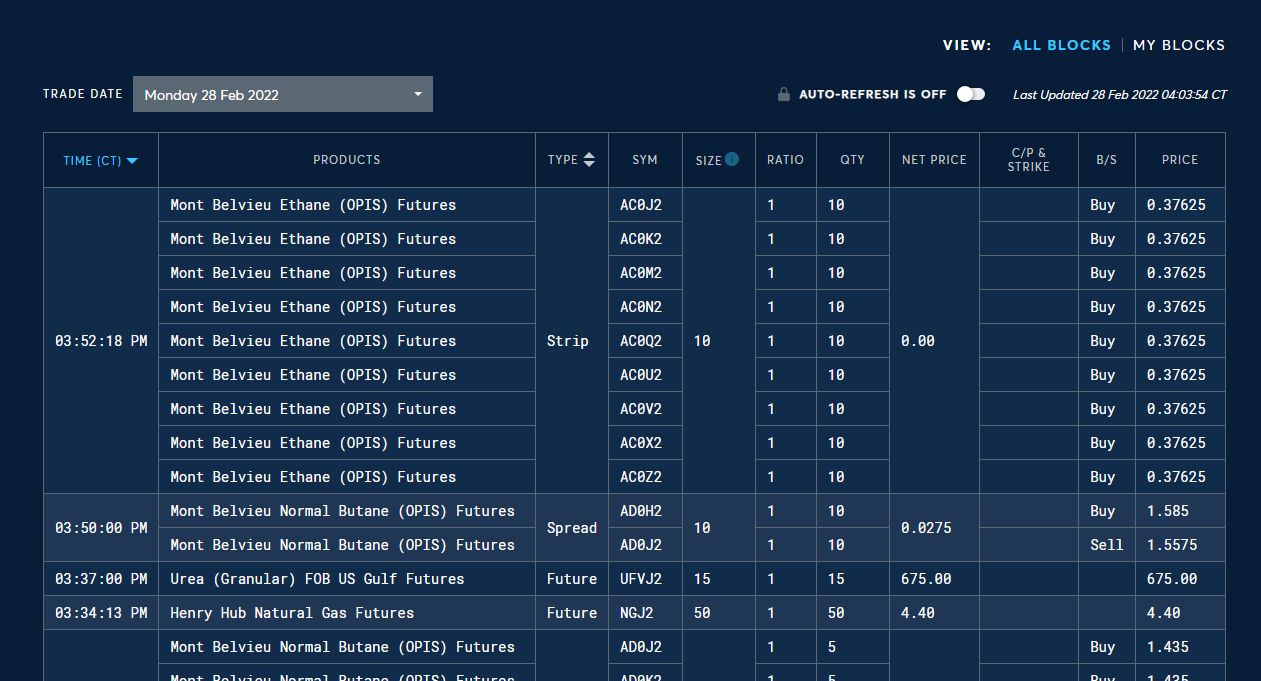
I'm trying to read it with Selenium:
// Load website
IWebDriver driver = new ChromeDriver();
driver.Navigate().GoToUrl("https://www.cmegroup.com/clearing/operations-and-deliveries/accepted-trade-types/block-data.html");
Thread.Sleep(1000);
// Get table
IWebElement table = driver.FindElement(By.XPath("//*[@id='main-content']/div/div[4]/div/div[2]"));
//driver.FindElement(By.CssSelector(".block-trades-table-wrapper'"));
// Loop table elements
IList<IWebElement> tableRow = table.FindElements(By.TagName("tr"));
IList<IWebElement> rowTD;
foreach (IWebElement row in tableRow)
{
rowTD = row.FindElements(By.TagName("td"));
}
Console.WriteLine("Test!");
After testing, I see that if I input a wrong Xpath I get an error:
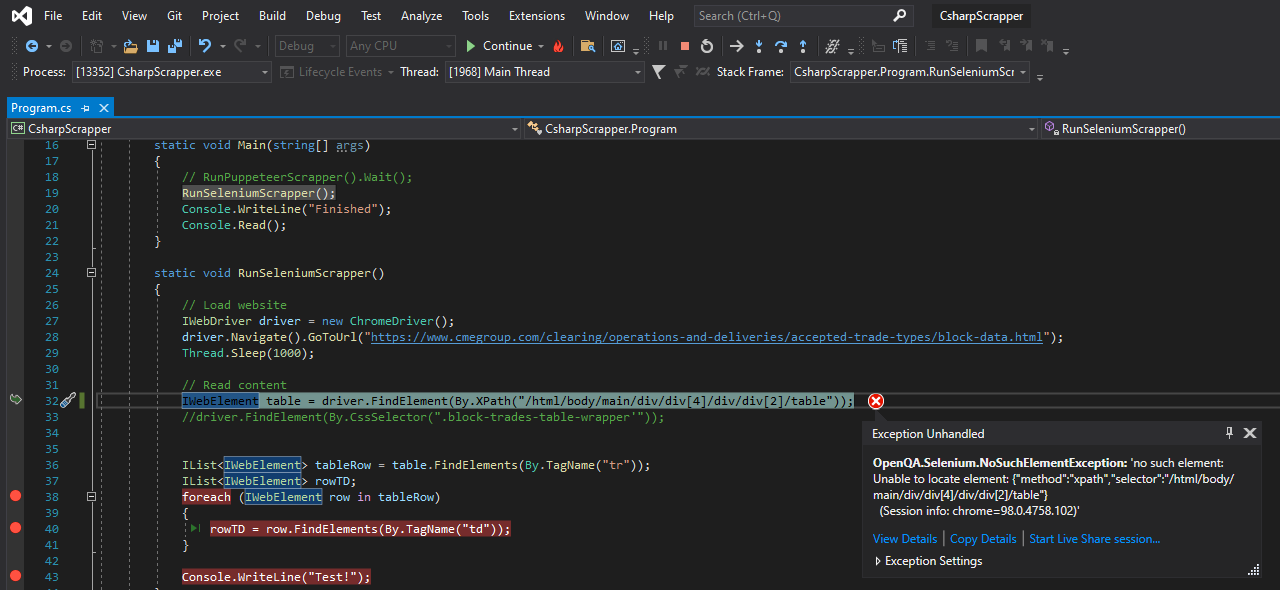
Here I'm not getting any error, so the Xpath should be correct. But I'm not getting anything to read.
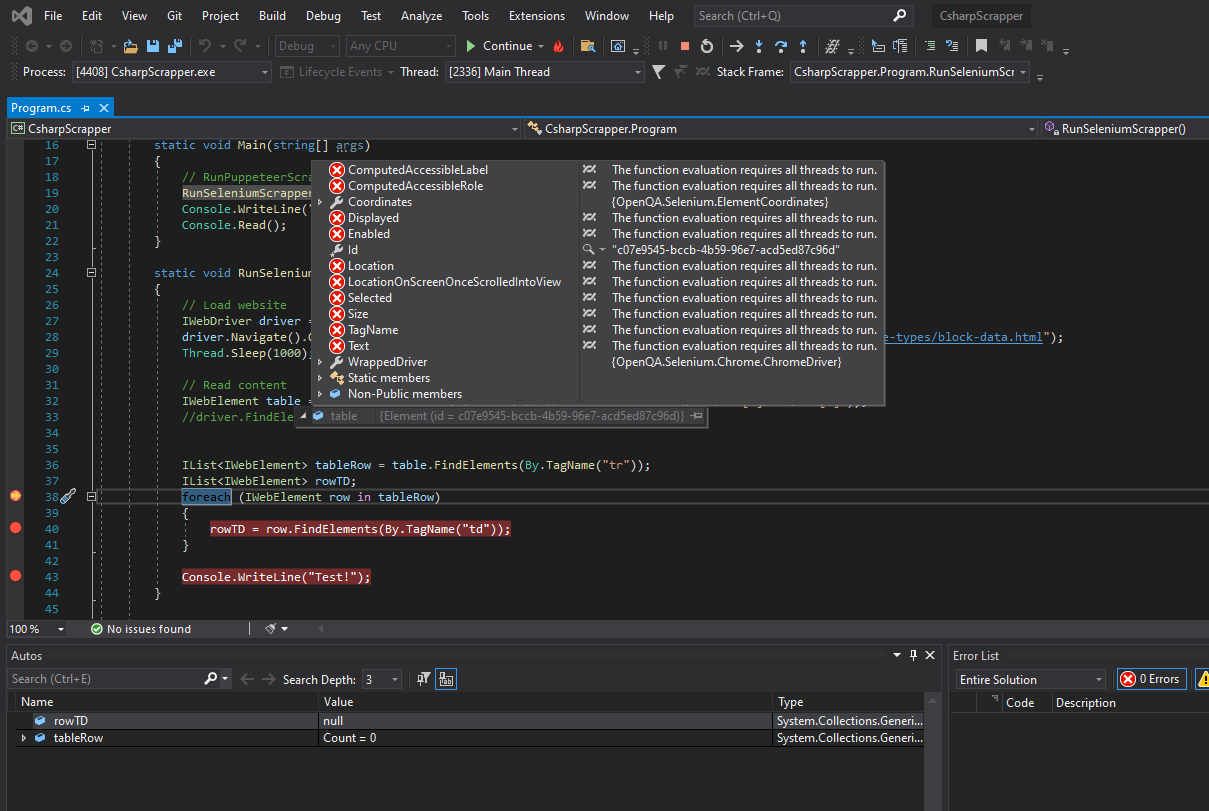
How can I read that table?
CodePudding user response:
@Adrian Hernando Solanas
For the first few Iteration, you won't find any record, because, if you see carefully, the first 2 tr does not have any td in it, as they are in thead
But when you continue Iterating, and when the code iteration comes within tbody you will start getting text for td
Also, add your code in try - catch block so that if a particular element is not present in any iteration, you can handle the situation as you need it.