I want to create a random ID variable considering an actual ID. That means that observations with the same id must have the same random ID. Let me put an example:
id var1var2
1 a 1
5 g 35
1 hf 658
2 f 576
9 d 54546
2 dg 76
3 g 5
3 g 5
5 gg 56
6 g 456
8v g 6
9 e 778795
The expected result is:
id var1var2id random
1 a 1 9
5 g 35 1
1 hf 658 9
2 f 576 8
9 d 54546 3
2 dg 76 8
3 g 5 7
3 g 5 7
5 gg 56 1
6 g 456 5
8v g 6 4
9 e 778795 3
CodePudding user response:
Here is a base R way with ave.
The random numbers are drawn between 1 and nrow(dat). Setting function sample argument size = 1 guarantees that all random numbers are equal by id.
set.seed(2022)
dat$random <- with(dat, ave(id, id, FUN = \(x) sample(nrow(dat), size = 1)))
Created on 2022-03-01 by the reprex package (v2.0.1)
Each id has only one random number.
split(data.frame(id = dat$id, random = dat$random), dat$id)
#> $`1`
#> id random
#> 1 1 4
#> 3 1 4
#>
#> $`2`
#> id random
#> 4 2 3
#> 6 2 3
#>
#> $`3`
#> id random
#> 7 3 7
#> 8 3 7
#>
#> $`5`
#> id random
#> 2 5 11
#> 9 5 11
#>
#> $`6`
#> id random
#> 10 6 4
#>
#> $`8v`
#> id random
#> 11 8v 6
#>
#> $`9`
#> id random
#> 5 9 12
#> 12 9 12
Created on 2022-03-01 by the reprex package (v2.0.1)
And the random numbers are uniformly distributed. Repeat the process above 10000 times, table the results and draw a bar plot to see it.
zz <- replicate(10000,
with(dat, ave(id, id, FUN = \(x) sample(nrow(dat), size = 1))))
barplot(table(as.integer(zz)))
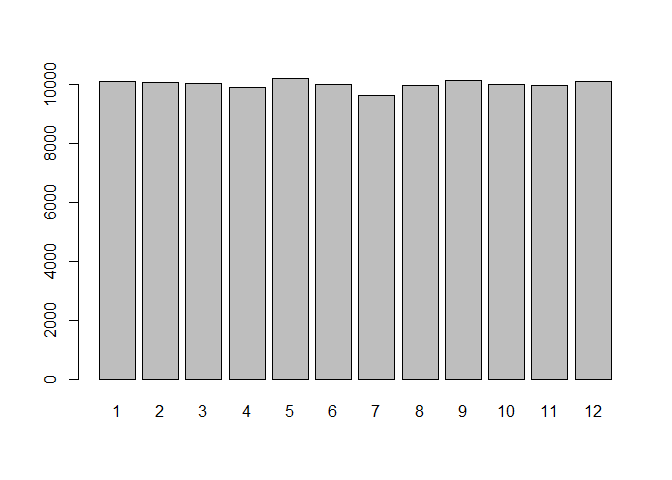
Created on 2022-03-01 by the reprex package (v2.0.1)
Data
dat <- read.table(header = T, text = "id var1 var2
1 a 1
5 g 35
1 hf 658
2 f 576
9 d 54546
2 dg 76
3 g 5
3 g 5
5 gg 56
6 g 456
8v g 6
9 e 778795")
Created on 2022-03-01 by the reprex package (v2.0.1)
CodePudding user response:
Just create a random group id for id and merge to the original data.
library(data.table)
library(tidyverse)
dt <- fread("
id var1 var2
1 a 1
5 g 35
1 hf 658
2 f 576
9 d 54546
2 dg 76
3 g 5
3 g 5
5 gg 56
6 g 456
8v g 6
9 e 778795
")
uq <- unique(dt$id)
set.seed(1)
uqid <- sample(1:length(unique(dt$id)), replace = F)
dt1 <- data.table(id = uq , random = uqid)
left_join(dt, dt1, by = "id" )
> left_join(dt, dt1, by = "id" )
id var1 var2 random
1: 1 a 1 1
2: 5 g 35 4
3: 1 hf 658 1
4: 2 f 576 7
5: 9 d 54546 2
6: 2 dg 76 7
7: 3 g 5 5
8: 3 g 5 5
9: 5 gg 56 4
10: 6 g 456 3
11: 8v g 6 6
12: 9 e 778795 2
It is like using a mapping table to create a new column but using join instead.
CodePudding user response:
To create a new id by group, use match with sample, or cur_group_id in dplyr. The ids will start from 1 until the number of total groups is reached.
Base R
dat$random_id <- match(dat$id, sample(unique(dat$id)))
dplyr
library(dplyr)
dat %>%
group_by(id = factor(id, levels = sample(unique(id)))) %>%
mutate(random_id = cur_group_id())
output
id var1 var2 random_id
1 1 a 1 6
2 5 g 35 2
3 1 hf 658 6
4 2 f 576 4
5 9 d 54546 5
6 2 dg 76 4
7 3 g 5 7
8 3 g 5 7
9 5 gg 56 2
10 6 g 456 1
11 8 g 6 3
12 9 e 778795 5