The Key:Value pairs from the following dictionary is as follows
result.items()
dict_items([('subjectArea', 'Work'), ('txn-timestamp', '2022-01-05 11:31:10'), ('foundation', {'schema': 'AZ_FH_ELLIPSE', 'table': 'AZ_FND_MSF620', 'keys': [{'key': 'DSTRCT_CODE', 'value': 'RTK1'}, {'key': 'WORKORDER', 'value': '11358186'}], 'dataMart': {'dependencies': [{'schema': 'AZ_DM_WORK', 'table': 'DIM_WORK_ORDER'}, {'schema': 'AZ_DM_WORK', 'table': 'FACT_WORK_ITEM'}]}})])
Can someone let me know if its possible to convert the above into a Spark DataFrame? My apologies, I'mm not sure how to do a line break to make the code look neater
CodePudding user response:
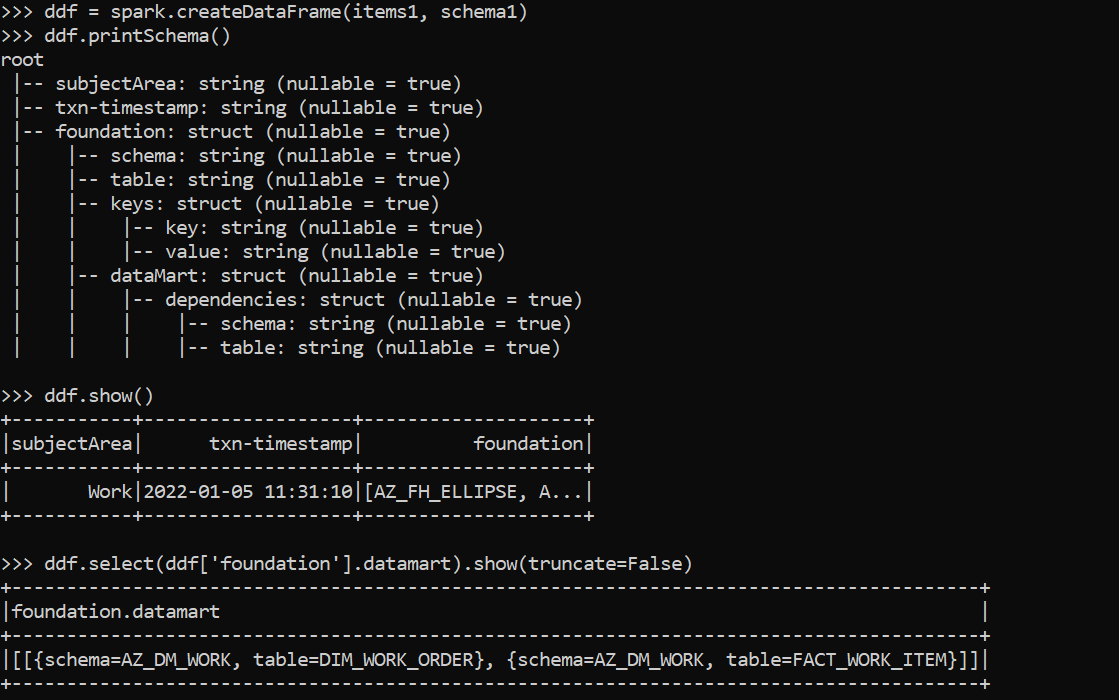
Here is the below pyspark code:
from pyspark.sql.types import *
items1 = [{'subjectArea': 'Work', 'txn-timestamp': '2022-01-05 11:31:10', 'foundation': {'schema': 'AZ_FH_ELLIPSE', 'table': 'AZ_FND_MSF620', 'keys': [{'key': 'DSTRCT_CODE', 'value': 'RTK1'}, {'key': 'WORKORDER', 'value': '11358186'}], 'dataMart': {'dependencies': [{'schema': 'AZ_DM_WORK', 'table': 'DIM_WORK_ORDER'}, {'schema': 'AZ_DM_WORK', 'table': 'FACT_WORK_ITEM'}]}}}]
schema1 = StructType([StructField('subjectArea',StringType()),StructField('txn-timestamp',StringType()),StructField('foundation',StructType([StructField('schema',StringType()),StructField('table',StringType()),StructField('keys',StructType([StructField('key',StringType()),StructField('value',StringType())])),StructField('dataMart',StructType([StructField('dependencies',StructType([StructField('schema',StringType()),StructField('table',StringType())]))]))]))])
ddf = spark.createDataFrame(items1, schema1)
ddf.printSchema()
ddf.show()
ddf.select(ddf['foundation'].datamart).show(truncate=False)