I looked up the instruction 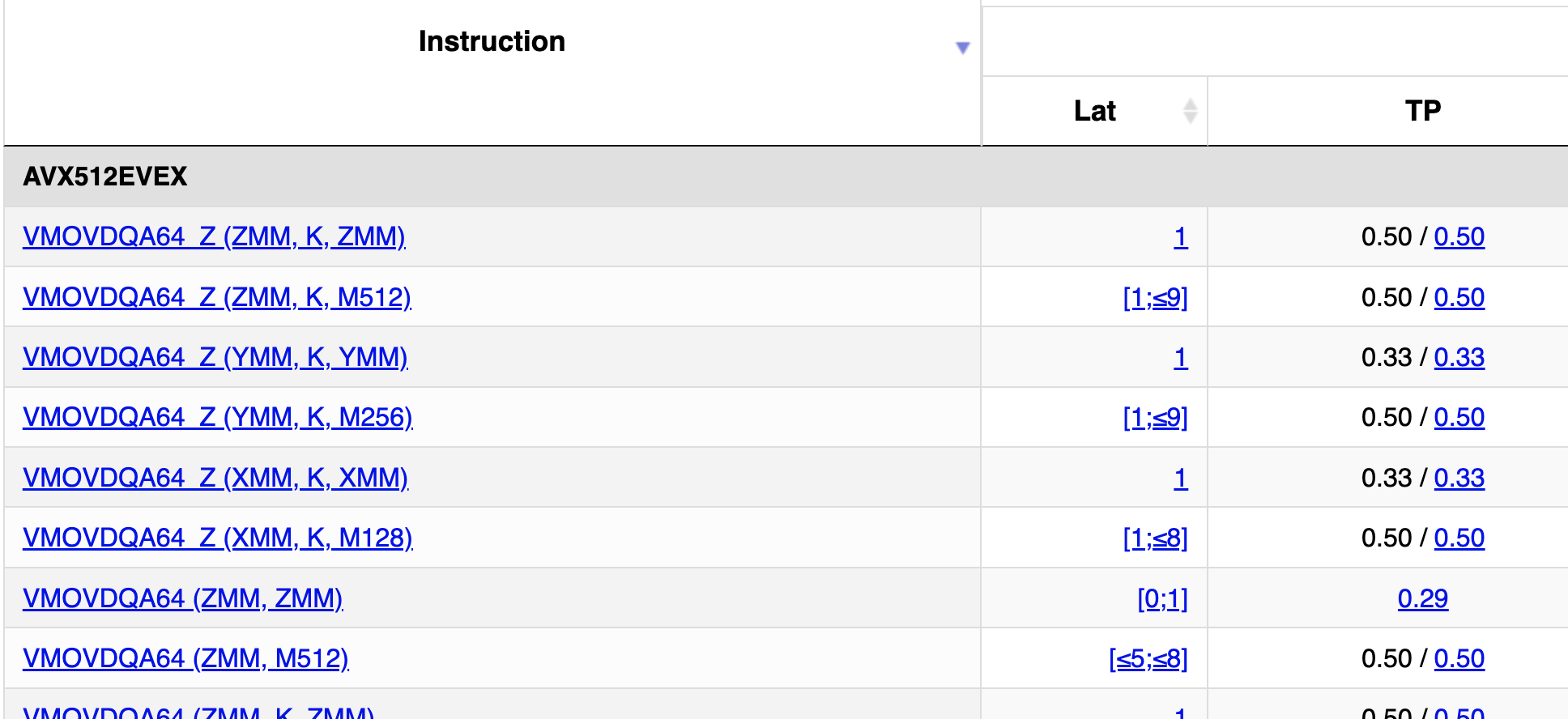
CodePudding user response:
The throughput is reciprocal throughput if running a large block of just that instruction. (Or with dependency-breaking instructions for cases like adc or div where you can't make back-to-back executions not have a data dependency because of implicit register inputs/outputs, especially FLAGS). So 0.5 means it can run once per 0.5 cycles, i.e. 2/clock, as expected for CPUs that we know have 2 load ports.
Why are there sometimes two numbers for latency, e.g. [≤10;≤11]?
See also What do multiple values or ranges means as the latency for a single instruction? which used a load ALU ALU instruction as an example. (I forgot how close a duplicate that was, not looking for it until I'd written the rest of this answer.)
Usually that indicates that latencies from different inputs to the output(s) can be different. e.g. a merge-masking load has to merge into the destination so that's one input, and the load address is another input (via integer registers). The recently-stored data in memory is a 3rd input (store-forwarding latency).
For cases like vector load-use latency, where the load result is in a different domain than the address registers, uops.info creates a dependency chain with an instruction sequence involving movd or vmovq rax, xmm0 to couple the load result back into the address for another load. It's hard to separately establish latencies for each part of that, so IIRC they assume that each other instruction in the chain is at least 1 cycle, and show the latency for the instruction under test as <= N, where N rest of dep chain adds up to the total cycles per iteration of the test code.
Look at the details page for one of those results, showing the test sequence used to measure it. Every number in the table is also a link. Those details pages tell you which operand is which, and break down the latencies from each input to each output. Let's look at a zero-masked vmovdqa64 512-bit load (VMOVDQA64_Z (ZMM, K, M512)) which in asm they tested using vmovdqa64 zmm0{k1}{z},ZMMWORD PTR [r14]. The listed latency is [1;≤9].
They number the operands as
- 1 (write-only): the ZMM destination.
- 2 (read-only): the
k0..7mask register - 3 (read-only): memory (later broken down into address vs. actual memory contents)
The 1 cycle latency part is latency from mask register to result, "Latency operand 2 → 1: 1". So the mask doesn't have to be ready until the load unit has fetched the data.
The <=9 is the latency from address base or index register to final ZMM result being ready.
Apparently with a store/reload case, bottlenecked on store-forwarding latency, "Latency operand 3 → 1 (memory): ≤6". They tested that with this sequence, described as "Chain latency: ≥6". vshufpd zmm is known to have 1 cycle latency, and I guess they're just counting the store as having 1 cycle latency? Like I said, they just assume everything is 1 cycle, even though it's kind of fishy to assign any latency at all to a store.
Code:
0: 62 d1 fd c9 6f 06 vmovdqa64 zmm0{k1}{z},ZMMWORD PTR [r14]
6: 62 71 fd 48 c6 e8 00 vshufpd zmm13,zmm0,zmm0,0x0
d: 62 51 95 48 c6 ed 00 vshufpd zmm13,zmm13,zmm13,0x0
14: 62 51 95 48 c6 ed 00 vshufpd zmm13,zmm13,zmm13,0x0
1b: 62 51 95 48 c6 ed 00 vshufpd zmm13,zmm13,zmm13,0x0
22: 62 51 95 48 c6 ed 00 vshufpd zmm13,zmm13,zmm13,0x0
29: 62 51 fd 48 11 2e vmovupd ZMMWORD PTR [r14],zmm13
(For throughput tests, they repeat the block multiple times to create an unrolled loop. But for latency tests they may just wrap a normal loop around it. nanobench is open-source so you could check.)
For the "Latency operand 3 → 1 (address, base register): ≤9" measurement, they say "Chain latency: ≥5". We know a vmovq r,x / vmovq x,r round-trip is more than 2 cycle latency, so the vmovq part of the chain here is probably more than a single cycle. That's why they over-estimate the load-use latency, with a conservative upper bound of 9 cycles.
0: 62 d1 fd c9 6f 06 vmovdqa64 zmm0{k1}{z},ZMMWORD PTR [r14]
6: c4 c1 f9 7e c4 vmovq r12,xmm0
b: 4d 31 e6 xor r14,r12
e: 4d 31 e6 xor r14,r12
11: 4d 31 e6 xor r14,r12
14: 4d 31 e6 xor r14,r12
they measure:
- Instructions retired: 6.0
- Core cycles: 14.0
- Reference cycles: 10.81
- UOPS_EXECUTED.THREAD: 7.0
14 cycles per iteration total, so they compute 14-5 = 9 cycles accounted for by the masked load. (Or fewer if the chain latency is actually longer than 5. The vmovq is probably actually 3 or 4 cycles, so 7 or 6 cycle SIMD load latency sound right. We know integer load-use latency is 5 cycles, and IIRC Intel's optimization manual says something about SIMD loads being 6 or 7 cycles. But this conservative upper bound of 9 is all we can really say for sure based purely on measurement, without extrapolation / guesswork.)
AVX-512 instruction naming.
"A64" is part of the AVX-512 vmovdqa64 instruction mnemonic, of course: check Intel's asm manual: https://www.felixcloutier.com/x86/movdqa:vmovdqa32:vmovdqa64. Remember that AVX-512 supports per-element merge- or zero-masking on (nearly) every instruction, so even movdqa and bitwise operations need an element size. That's also why AVX-512 bitwise booleans are vpord / q instead of just vpor (They could have used b/w/d/q naming for movdqa element sizes, but then we'd have vmovdqad or vmovdqaq, but I think we can be glad they didn't.)
Fortunately a32 vs. a64 doesn't make any performance difference, and only has any difference on the result when you're using masking, e.g. via _mm512_maskz_load_epi32( __mmask16 k, void * sa) vs. epi64 only taking a __mmask8. Or for smaller vector widths, only using fewer than 8 bits of a mask.
Zero-Masking vs. Merge Masking
op Z (ZMM, K, ZMM) vs op (ZMM, K, ZMM) is zero-masking vs. merge-masking. If you don't know how AVX-512 masking works, go read about it. e.g. Kirill Yukhin's presentation slides have an overview:
https://en.wikichip.org/w/images/d/d5/Intel_Advanced_Vector_Extensions_2015-2016_Support_in_GNU_Compiler_Collection.pdf
Reg-reg vmovdqa without masking (no k register) can be 0 latency (mov-elimination), but with masking it's always 1.
Fun fact: register-renaming for k0..k7 uses the same physical register file space as MMX/x87: https://travisdowns.github.io/blog/2020/05/26/kreg2.html