I have 2 DataFrames from 2 different csv file and both file have let's say 5 columns each. And I need to lookup 1 column from the second DataFrame into the first DataFrame so the first DataFrame will has 6 columns and lookup using the ID.
Example are as below:
import pandas as pd
data = [[6661, 'Lily', 21, 5000, 'USA'], [6672, 'Mark', 32, 32500, 'Canada'], [6631, 'Rose', 20, 1500, 'London'],
[6600, 'Jenifer', 42, 50000, 'London'], [6643, 'Sue', 27, 8000, 'Turkey']]
ds_main = pd.DataFrame(data, columns = ['ID', 'Name', 'Age', 'Income', 'Country'])
data2 = [[6672, 'Mark', 'Shirt', 8.5, 2], [6643, 'Sue', 'Scraft', 2.0, 5], [6661, 'Lily', 'Blouse', 11.9, 2],
[6600, 'Jenifer', 'Shirt', 9.8, 1], [6631, 'Rose', 'Pants', 4.5, 2]]
ds_rate = pd.DataFrame(data2, columns = ['ID', 'Name', 'Product', 'Rate', 'Quantity'])
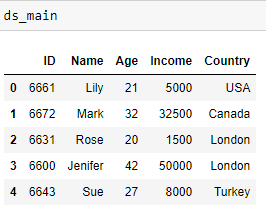
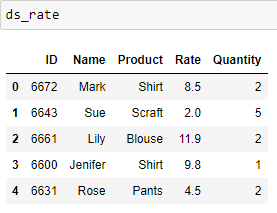
I wanted to lookup the 'Rate' from ds_rate into the ds_main. However, I wanted the rate to be place in the middle of the ds_main DataFrame.
The result should be as below:
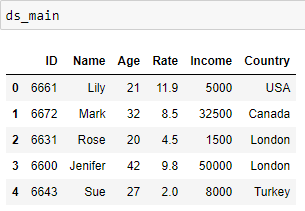
I have tried using merge and insert, still unable to get the result that I wanted. Is there any easy way to do it?
CodePudding user response:
You could use set_index loc to get "Rate" sorted according to its "ID" in ds_main; then insert:
ds_main.insert(3, 'Rate', ds_rate.set_index('ID')['Rate'].loc[ds_main['ID']].reset_index(drop=True))
Output:
ID Name Age Rate Income Country
0 6661 Lily 21 11.9 5000 USA
1 6672 Mark 32 8.5 32500 Canada
2 6631 Rose 20 4.5 1500 London
3 6600 Jenifer 42 9.8 50000 London
4 6643 Sue 27 2.0 8000 Turkey
CodePudding user response:
Assuming 'ID' is unique
ds_main.iloc[:, :3].merge(ds_rate[['ID', 'Rate']]).join(ds_main.iloc[:, 3:])
ID Name Age Rate Income Country
0 6661 Lily 21 11.9 5000 USA
1 6672 Mark 32 8.5 32500 Canada
2 6631 Rose 20 4.5 1500 London
3 6600 Jenifer 42 9.8 50000 London
4 6643 Sue 27 2.0 8000 Turkey