Grouping the data frames by the month that are saved in the "date" field, and agreeing two columns, respectively "wealth_avg" and "state_money_avg"
what I have: df

what I expected:
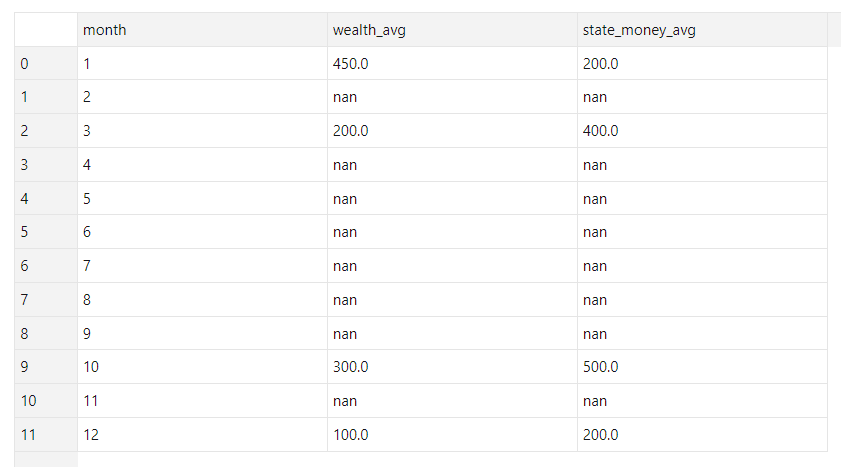
recap: i expect an array with 12 objects, where each object has the number of months: 1 meaning January, 2 means February and so on, and "wealth_avg" that are the avg of the wealth and "state_money_avg" that are the avg of the state_money, all this being calculated from that dateframe grouped by month.
- months that are not in the data frame must be null/nan (doesn't matter which one, preferably null) when we return the result
simple code ex:
import pandas as pd
# intialise data of lists.
data = {
'name':['Tom', 'nick', 'krish', 'jack', 'alexander'],
'age':[20, 20, 20, 20, 20],
'date':["2002-01-02", "2002-12-10", "2002-01-01", "2002-
03-01", "2002-10-09"],
'wealth': [500, 100, 400, 200, 300],
'state_money': [100, 200, 300, 400, 500],
}
# Create DataFrame
df = pd.DataFrame(data)
# Print the output.
df
CodePudding user response:
Assuming date column's type is datetime, you can extract months to a different column:
df["month"] = df["date"].dt.month
Then group by month column and find the averages:
df.groupby("month").agg(wealth_avg=("wealth", "mean"), state_money_avg=("state_money", "mean"))