I am working with two dataframes:
df - contains multiple rows with data about scientific articles, including a magazine_id which is connected to the ids in the second dataframe
magazines - contains only 2 columns: id and title
In the magazines dataframe there are duplicate titles.
I am unsure about how to change the ids referenced in the first dataframe to the ids that will be kept after the duplicates are removed.
df = pd.Dataframe({'id': [1003, 1009, 1010, 1034],
'title': ['Article1', 'Article2', 'Article3', 'Article4'],
'magazine_id': [1, 2, 3, 4]})
magazines = pd.Dataframe({'id': [1, 2, 3, 4],
'title': ['Mag1','Mag1','Mag3','Mag4']})
So from magazines, entry with id = 2 should be deleted because it has the same title as id = 1.
The output for df should be:
id title magazine_id
1003 'Article1' 1
1009 'Article2' 1
1010 'Article3' 3
1034 'Article4' 4
CodePudding user response:
Since your question is not clear I made a scenario. If it is your case my suggestion is that first merge the dfs then use drop_duplicates. See the following:
main_df = pd.DataFrame({'title_id':[1,2,3,4,5], 'authors': ['w', 'e', 'w','e','w']})
titles = pd.DataFrame({'id': [1,2,3,4,5], 'title': ['a', 'b', 'a', 'b','a']})
main_df.merge(titles, left_on='title_id', right_on='id').drop_duplicates(['title', 'authors'])
main_df:
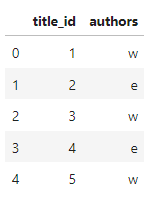
titles df with duplicates:

The result:
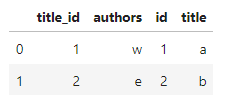
CodePudding user response:
Use drop_duplicates to get rid of duplicate titles, and use ffill:
magazines = magazines.drop_duplicates(subset=['title'])
df.loc[~df['magazine_id'].isin(magazines['id']), 'magazine_id'] = np.nan
df['magazine_id'] = df['magazine_id'].ffill().astype(int)
Output:
>>> df
id title magazine_id
0 1003 Article1 1
1 1009 Article2 1
2 1010 Article3 3
3 1034 Article4 4
>>> magazines
id title
0 1 Mag1
2 3 Mag3
3 4 Mag4
CodePudding user response:
- have created two data frames that align with your problem statement
- de-dupe titles, keeping list of IDs that were used
- then map (merge) to re-align title_id of second data frame
import pandas as pd
import numpy as np
df = pd.DataFrame({"id": range(10), "title": np.random.choice(list("ABCDEFG"), 10)})
df2 = pd.DataFrame(
{"content_id": range(100), "title_id": np.random.choice(range(10), 100)}
)
# drop duplicates, keep original ids as list
df = (
df.groupby("title").agg(ids=("id", list)).reset_index().assign(id=lambda d: d.index)
)
# map title ids in second data frame to newly de-duped ids
df2 = (
df.loc[:, ["id", "ids"]]
.explode("ids")
.merge(df2, left_on="ids", right_on="title_id")
.drop(columns=["id", "title_id"])
.rename(columns={"ids": "title_id"})
)