I have a DataFrame df2 with columns currencies and c_codes.
Each row in the currencies column is a list of one or more dictionaries. I want to extract the value for the key code in each dictionary within each list in each row of currencies and transfer the code values to a different column of the DataFrame c_codes
Case in point:
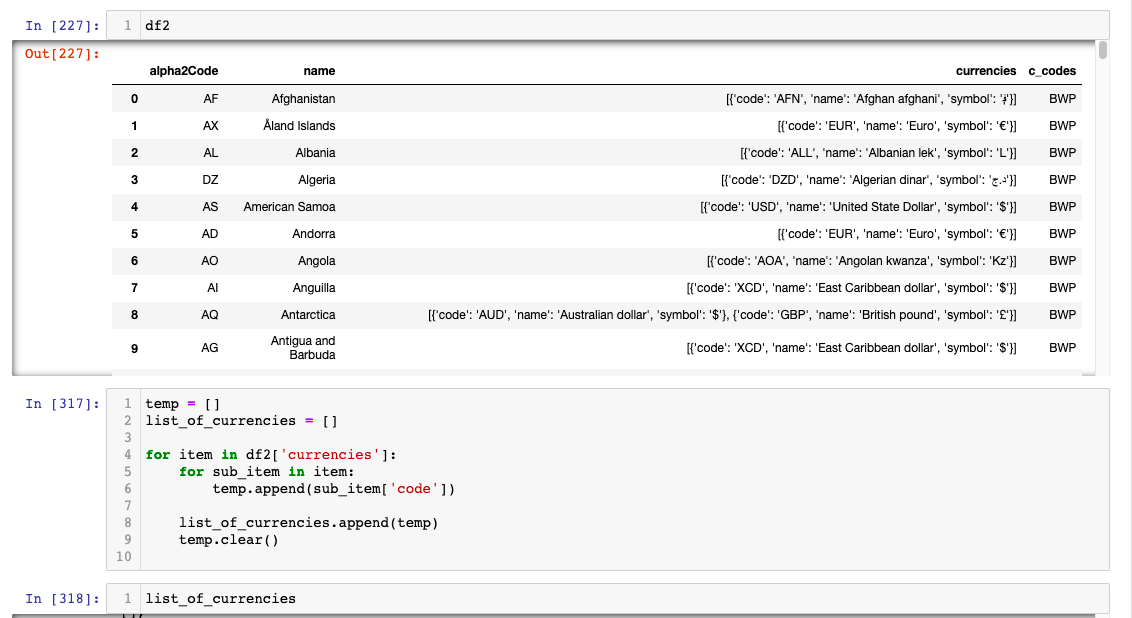
From df2['currencies'][0] I want to extract the code value AFN and transfer it to df2['c_codes'][0]
Similarly, if there are multiple code values for a row, such as df2['currencies'][8] then I want to extract a list of code values ['AUD','GBP'] and transfer the list to df2['c_codes][8]
Each entry in c_codes can be a list for this purpose.
Here's my code:
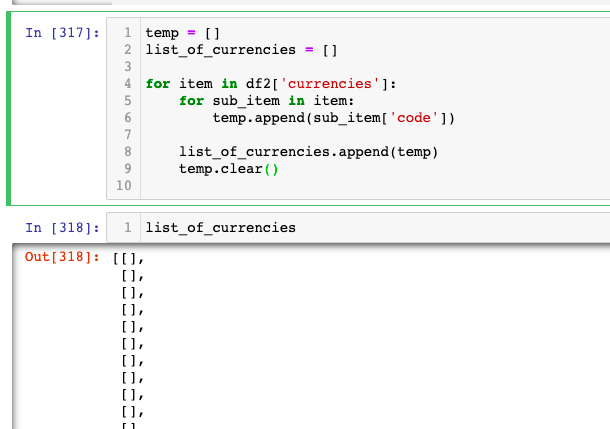
I have tried using a loop to grab the code values in each dict. in each row and append them to a list temp. Then append the list temp to a bigger list list_of_currencies so I get a list with lists of codes corresponding to each row. Then I clear the temp list so it can grab the next row of code and so on.
However, the code returns the list_of_currencies as empty. I have tried playing around with the looping, temp, lists, etc. but it just returns empty list or else a list of all appended codes without sub-lists.
I want a list returned with sub-lists of codes so I can assign each sub-list to a corresponding row in c_codes column.
What am I doing wrong? Is there a simpler way to do this?
CodePudding user response:
Here's how I would solve your problem, given that I understood it all correctly:
import pandas
df = pandas.DataFrame({
"x": ["A", "B", "C"],
"currencies": [[{"code": "x"}, {"code": "y"}], [{"code": "u"}], [{"code": "v"}]]
})
print(df)
> x currencies
0 A [{'code': 'x'}, {'code': 'y'}]
1 B [{'code': 'u'}]
2 C [{'code': 'v'}]
df["c_codes"] = df["currencies"].apply(lambda x: [i["code"] for i in x])
print(df)
> x currencies c_codes
0 A [{'code': 'x'}, {'code': 'y'}] [x, y]
1 B [{'code': 'u'}] [u]
2 C [{'code': 'v'}] [v]
What this apply method does is it iterates over the values in currencies and applies the lambda function to it: for each input (in this case a list of dicts) return a list of just the values of each code value. These results are then saved to the new column c_codes.
CodePudding user response:
I think you can use explode to expand the list of objects, and .str to get the code value, for a vectorized (read: really fast) solution:
df['c_codes'] = df['currencies'].explode().str['code'].groupby(level=0).agg(list).str.join(', ')
Output (based on sample data at the bottom of this answer):
>>> df
currencies c_codes
0 [{'code': 'AFN', 'name': 'Afghan afghani'}] AFN
1 [{'code': 'EUR', 'name': 'Euro'}] EUR
2 [{'code': 'AUD', 'name': 'Australian dollar'}, {'code': 'GBP', 'name': 'British pound'}] AUD, GBP
3 [{'code': 'XCD', 'name': 'East Carribean dollar'}] XCD
If you want actual lists in the c_codes column and not just comma-separate strings, just omit the .str.join part:
df['c_codes'] = df['currencies'].explode().str['code'].groupby(level=0).agg(list)
Output:
>>> df
currencies c_codes
0 [{'code': 'AFN', 'name': 'Afghan afghani'}] [AFN]
1 [{'code': 'EUR', 'name': 'Euro'}] [EUR]
2 [{'code': 'AUD', 'name': 'Australian dollar'}, {'code': 'GBP', 'name': 'British pound'}] [AUD, GBP]
3 [{'code': 'XCD', 'name': 'East Carribean dollar'}] [XCD]
Sample data for testing above code:
df = pd.DataFrame({'currencies': [
[{'code':'AFN','name':'Afghan afghani'}],
[{'code':'EUR','name':'Euro'}],
[{'code':'AUD','name':'Australian dollar'},{'code':'GBP','name':'British pound'}],
[{'code':'XCD','name':'East Carribean dollar'}]]})