I'm trying to extract information from 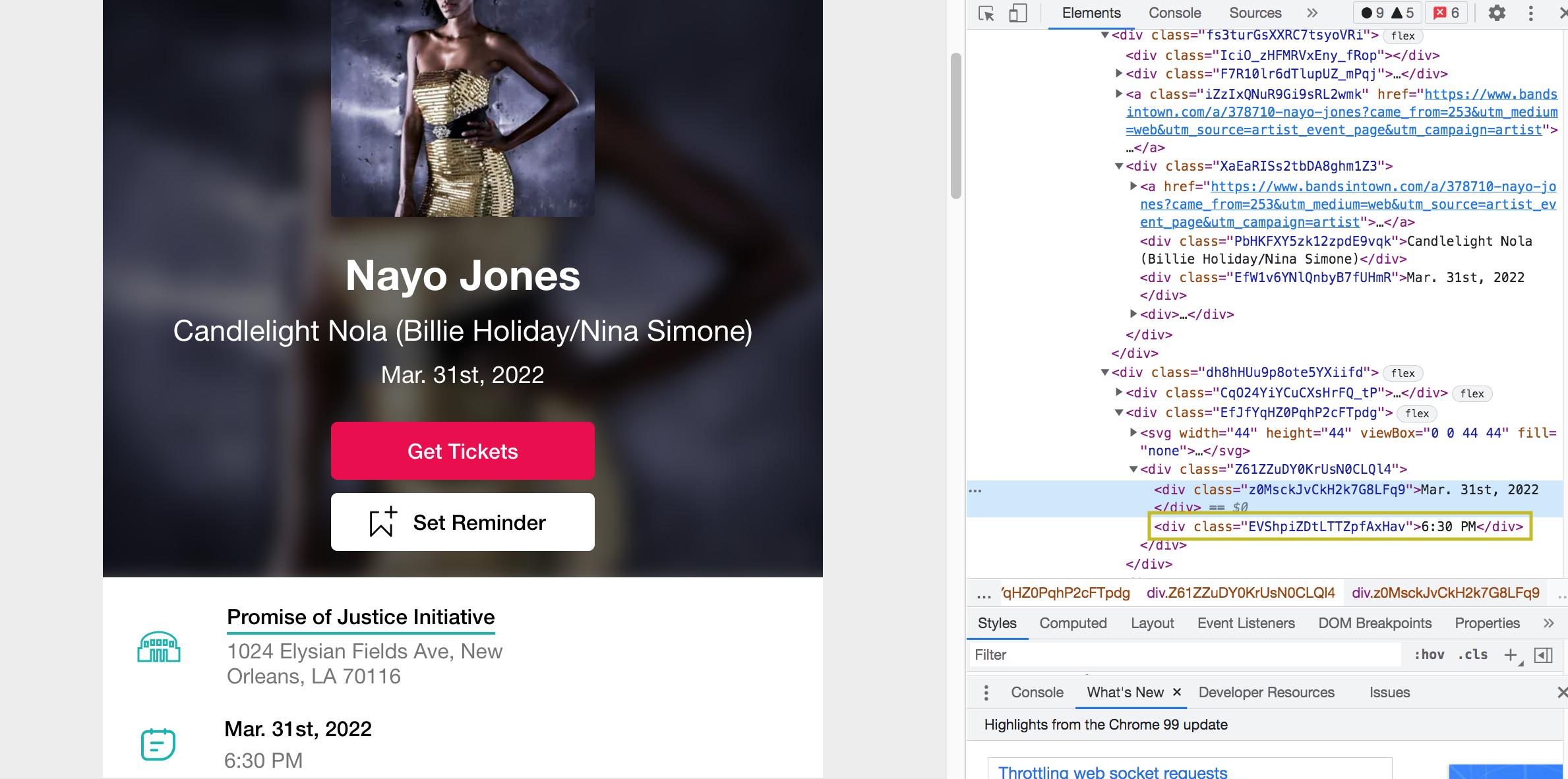
Here's what I've tried:
#Get First Date (Date at top of the page)
try:
first_date = driver.find_elements_by_css_selector('a[href^="https://www.bandsintown.com/a/"] div div')
first_date = first_date[0].text
except (ElementNotVisibleException, NoSuchElementException, TimeoutException):
print ("first_date doesn't exist")
continue
#Get time. This will the first sibling of the second instance of date
try:
event_time = driver.find_elements_by_xpath("//div[text()='" first_date "'][1]/following-sibling::div")
print(event_time[0].text)
except (ElementNotVisibleException, NoSuchElementException, TimeoutException):
continue
However, this is not getting me what I want. What am I doing wrong here? I'm looking for a way to get the first sibling of the second instance using Xpath.
CodePudding user response:
It seems it is first element with PM / AM so I would use find_element with
'//div[contains(text(), " PM") or contains(text(), " AM")]'
like this
item = driver.find_element(By.XPATH, '//div[contains(text(), " PM") or contains(text(), " AM")]')
print(item.text)
I use space before PM/AM to make sure it is not inside word.
Your xpath works when I add ( ) so it first gets divs and later select by index.
Without () it may treats [text()="..."][1] like [text()="..." and 1].
And it needs [2] instead of [1] because xpath start counting at 1, not 0
"(//div[text()='" first_date "'])[2]/following-sibling::div"
Full working example
from selenium import webdriver
from selenium.webdriver.common.by import By
#from webdriver_manager.chrome import ChromeDriverManager
from webdriver_manager.firefox import GeckoDriverManager
import time
url = 'https://www.bandsintown.com/e/103275458-nayo-jones-at-promise-of-justice-initiative?came_from=253&utm_medium=web&utm_source=city_page&utm_campaign=event'
#driver = webdriver.Chrome(executable_path=ChromeDriverManager().install())
driver = webdriver.Firefox(executable_path=GeckoDriverManager().install())
driver.get(url)
time.sleep(5)
item = driver.find_element(By.XPATH, '//div[contains(text(), " PM") or contains(text(), " AM")]')
print(item.text)
print('---')
first_date = driver.find_elements(By.CSS_SELECTOR, 'a[href^="https://www.bandsintown.com/a/"] div div')
first_date = first_date[0].text
event_time = driver.find_elements(By.XPATH, "(//div[text()='" first_date "'])[2]/following-sibling::div")
print(event_time[0].text)
CodePudding user response:
The following xpath will give you date and time.
date:
print(driver.find_element_by_xpath("//a[text()='Promise of Justice Initiative']/following::div[4]").text)
time:
print(driver.find_element_by_xpath("//a[text()='Promise of Justice Initiative']/following::div[5]").text)
or your use.
print(driver.find_element_by_xpath("
//a[contains(@href,'https://www.bandsintown.com/v/')]/following::div[contains(text(), 'PM') or contains(text(), 'AM')]").text)