I have data like this:
df<-structure(list(a = c(1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0), b = c(0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 1, 0, 0, 0)), row.names = c(NA, -19L), class = c("tbl_df",
"tbl", "data.frame"))
I would like to replace values in column A based on column B. If column B has a "1" in it, I want to replace the row in column A with a 1.
I know this can do that:
df<-df %>%mutate(a=ifelse(str_detect(b,"1"),1,0))
The problem is, this replaces everything in column A based on those rules, overwriting what was already there. I only want to replace A if it didn't already have a "1". So my expected output would be:
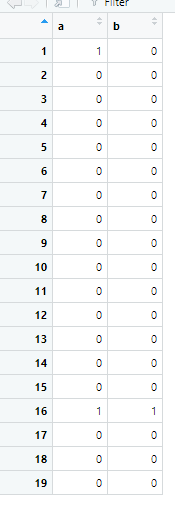
CodePudding user response:
We may need just | on the binary column to replace the values in 'a' where 'b' is also 1
library(dplyr)
df %>%
mutate(a = (a|b))
-output
# A tibble: 19 × 2
a b
<int> <dbl>
1 1 0
2 0 0
3 0 0
4 0 0
5 0 0
6 0 0
7 0 0
8 0 0
9 0 0
10 0 0
11 0 0
12 0 0
13 0 0
14 0 0
15 0 0
16 1 1
17 0 0
18 0 0
19 0 0
Or in base R
df$a[df$b == 1] <- 1