I currently have a data frame which contains Name of Station, Date of Rainfall, Amount of Rainfall (Example attached) I am interested in exploring the number of days (and/or months) it takes each Station to reach a particular amount of rainfall. For example:
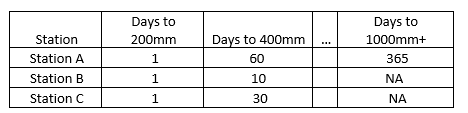
Is it possible to obtain an output like the one above based on a dataset like the example one? My initial thought process is to filter each station individually, join to a calendar dataframe which extracts the min and max from that range, count the days between them and use a case_when to categorize them. This approach seems a bit convoluted and would appreciate any guidance as to what would be a better approach.
Thanks for the suggestions!
Example Dataset:
Example <- structure(list(Name.Station = c("Station A", "Station A", "Station A",
"Station A", "Station A", "Station B", "Station B", "Station B",
"Station C", "Station C", "Station C", "Station C"), Rainfall.Date = c("7/10/2020",
"8/12/2020", "8/01/2021", "25/06/2021", "26/10/2021", "7/01/2020",
"22/01/2020", "5/02/2020", "5/09/2020", "5/10/2020", "5/11/2020",
"5/12/2020"), Rainfall.Amount = c(210, 210, 208.47, 208.16, 203.67,
227.49, 225, 222.54, 250, 250, 246.18, 245.15)), class = "data.frame", row.names = c(NA,
-12L))
CodePudding user response:
by station you could calculate the cumsum of rainfall greater than the threshold in mm. Then calculate the length of the sequence of days from start date to the date which is maximum in the cumsum.
First of all, though, your dates should be formatted properly.
Example <- transform(Example, Rainfall.Date=as.Date(Rainfall.Date, '%d/%m/%Y'))
do.call(rbind, by(Example, Example$Name.Station, \(x) {
f <- \(mm, x.=x) {
mx <- which.max(cumsum(x.$Rainfall.Amount) > mm)
length(do.call(seq.Date, c(as.list(range(x.$Rainfall.Date[1:mx])), 1)))
}
ds <- seq.int(200, 1e3, 200) ## sequence of 200, 400, ... , 1000mm
r <- t(vapply(ds, f, 0))
data.frame(Name.Station=el(x$Name.Station), `colnames<-`(r, paste0('d_', ds)))
}))
# Name.Station d_200 d_400 d_600 d_800 d_1000
# Station A Station A 1 63 94 262 385
# Station B Station B 1 16 30 1 1
# Station C Station C 1 31 62 92 1
Note: R >= 4.1 used.
CodePudding user response:
Here is a tidyverse approach:
library(dplyr)
library(tidyr)
Example %>%
group_by(Name.Station) %>%
mutate(Rainfall.Date = as.Date(Rainfall.Date, "%d/%m/%Y"),
days = cumsum(c(1, diff(Rainfall.Date))),
crainfall = cumsum(Rainfall.Amount),
fi = {x <- seq(0, 1000, 200); x[findInterval(crainfall, x)]}) %>%
pivot_wider(id_cols = Name.Station, names_from = fi, values_from = days, names_glue = {"days_to_{fi}_mm"})
# A tibble: 3 x 6
# Groups: Name.Station [3]
Name.Station days_to_200_mm days_to_400_mm days_to_600_mm days_to_800_mm days_to_1000_mm
<chr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Station A 1 63 94 262 385
2 Station B 1 16 30 NA NA
3 Station C 1 31 62 92 NA