I have a problem. This is my initial example data base:
nam <- c("Marco", "Clara")
code <- c("The liquidations code for Marco are: 51-BMR05, 74-VAD08, 176-VNF09.",
"The liquidations code for Clara are: 88-BMR05, 90-VAD08, 152-VNF09.")
df <- data.frame(name,code)
That look like this:

So what I want is for the codes after the double dot to be separated and be a record with the same name. That is to say that the database is transformed and finished in this way:
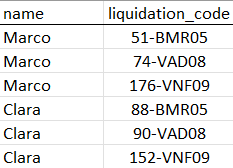
I need to know if there is any way in R that can help me to facilitate and speed up this work. I did the examples in excel. In advance, I thank everyone for their help.
CodePudding user response:
Here is a tidy solution:
library(tidyverse)
df %>%
# Remove text and trailing dot
mutate(
code = stringr::str_remove(
string = code,
pattern = "The liquidations code for .* are: "
),
code = stringr::str_remove(
string = code,
pattern = "\\.$"
)
) %>%
# Split the codes (results in list column)
mutate(code = stringr::str_split(code, ", ")) %>%
# Turn list column into new rows
unnest(code)
#> # A tibble: 6 × 2
#> name code
#> <chr> <chr>
#> 1 Marco 51-BMR05
#> 2 Marco 74-VAD08
#> 3 Marco 176-VNF09
#> 4 Clara 88-BMR05
#> 5 Clara 90-VAD08
#> 6 Clara 152-VNF09
Created on 2022-03-28 by the reprex package (v2.0.1)
Data
Same code as posted by OP, but fixed nam to name:
name <- c("Marco", "Clara")
code <- c("The liquidations code for Marco are: 51-BMR05, 74-VAD08, 176-VNF09.",
"The liquidations code for Clara are: 88-BMR05, 90-VAD08, 152-VNF09.")
df <- data.frame(name,code)
CodePudding user response:
We could use str_extract_all to extract all the codes in list and then unnest
library(dplyr)
library(stringr)
library(tidyr)
df %>%
mutate(code = str_extract_all(code, "\\d -[A-Z0-9] ")) %>%
unnest(code)
-output
# A tibble: 6 × 2
name code
<chr> <chr>
1 Marco 51-BMR05
2 Marco 74-VAD08
3 Marco 176-VNF09
4 Clara 88-BMR05
5 Clara 90-VAD08
6 Clara 152-VNF09
CodePudding user response:
I accomplished the output with this:
df1 <- separate_rows(df, code, sep=', ', convert = TRUE)
df1$liquidation_code <- gsub('The liquidations code for Marco are: |The liquidations code for Clara are: |\\.','',df1$code)
df1 <- df1[ , !(colnames(df1) %in% c('code'))]
df1
CodePudding user response:
Something like this should help
library(tidyverse)
#> Warning: package 'tidyr' was built under R version 4.1.3
#> Warning: package 'readr' was built under R version 4.1.3
#> Warning: package 'dplyr' was built under R version 4.1.3
name <- c("Marco", "Clara")
code <- c("The liquidations code for Marco are: 51-BMR05, 74-VAD08, 176-VNF09.",
"The liquidations code for Clara are: 88-BMR05, 90-VAD08, 152-VNF09.")
df_example <- data.frame(name,code)
df_example |>
mutate(codes = str_extract(code,pattern = "(?<=:). ") |>
str_split(',')) |>
unnest(codes) |>
mutate(codes = codes |> str_squish() |> str_remove('\\.'))
#> # A tibble: 6 x 3
#> name code codes
#> <chr> <chr> <chr>
#> 1 Marco The liquidations code for Marco are: 51-BMR05, 74-VAD08, 176-VNF0~ 51-B~
#> 2 Marco The liquidations code for Marco are: 51-BMR05, 74-VAD08, 176-VNF0~ 74-V~
#> 3 Marco The liquidations code for Marco are: 51-BMR05, 74-VAD08, 176-VNF0~ 176-~
#> 4 Clara The liquidations code for Clara are: 88-BMR05, 90-VAD08, 152-VNF0~ 88-B~
#> 5 Clara The liquidations code for Clara are: 88-BMR05, 90-VAD08, 152-VNF0~ 90-V~
#> 6 Clara The liquidations code for Clara are: 88-BMR05, 90-VAD08, 152-VNF0~ 152-~
Created on 2022-03-28 by the reprex package (v2.0.1)
CodePudding user response:
Using regex from stringr
#build your df
name <- c("Marco", "Clara")
code <- c("The liquidations code for Marco are: 51-BMR05, 74-VAD08, 176-VNF09.",
"The liquidations code for Clara are: 88-BMR05, 90-VAD08, 152-VNF09.")
df <- data.frame(name,code)
# Processing
codes = stringr::str_extract_all(df$code, "([:alnum:] -[:alnum:] )")
names(codes) <- c(df$name)
liquidation_code = unlist(codes)
fix_names = substr(names(liquidation_code),1,nchar(names(liquidation_code))-1)
fix_df = data.frame(names = fix_names,liquidation_code)
names liquidation_code
Marco1 Marco 51-BMR05
Marco2 Marco 74-VAD08
Marco3 Marco 176-VNF09
Clara1 Clara 88-BMR05
Clara2 Clara 90-VAD08
Clara3 Clara 152-VNF09