Below is my example, let me explain what I am trying to do, although it is not working as I want it to.
I need to find all instances where there are 2 unique values in column z on the same date for the same person. However, I need to find where a specific list of values in column z are present.
library(tidyverse)
x <- c("Person A","Person A","Person A","Person A","Person A","Person A")
y <- c("2022-01-01","2022-01-01","2022-01-20","2022-02-01","2022-02-01","2022-02-01")
z <- c("A","D","A","A","C","B")
df <- data.frame(x,y,z)
df
df %>%
group_by(x,y) %>%
mutate(unique_z = n_distinct(z)) %>%
# ungroup() %>%
filter(unique_z > 1,
z %in% c("C","B"))
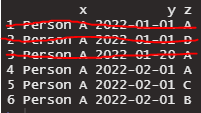
Below is an image of what I want the output to be, but I cannot figure it out.
Row 1 and 2 should be removed because even though it is 2 unique values of z on the same date for the same person, it does not include "C" or "B".
Row 3 is removed because it is only one unique value for that person and date.
Rows 4, 5, and 6 all should stay because that person, date combination has three unique values of z. Also, "C" and/or "B" occur in these rows. For some reason, row 4 is being removed every time. I to see the other values of z on that person, date combination. I thought grouping and filtering would do this, but it does not seem to the way I am doing it.
CodePudding user response:
You need to use any to check for the presence of c("B", "C") within each group and not at each row; see below:
library(dplyr)
df %>%
group_by(x,y) %>%
mutate(unique_z = n_distinct(z)) %>%
filter(unique_z > 1,
any(z %in% c("B","C")))
## any(z %in% c("C")) & any(z %in% c("B")))
## use this one instead if you want B and C present at the same time ...
## ... and two B's or two C's are not desired
# # A tibble: 3 x 4
# # Groups: x, y [1]
# x y z unique_z
# <fct> <fct> <fct> <int>
# 1 Person A 2022-02-01 A 3
# 2 Person A 2022-02-01 C 3
# 3 Person A 2022-02-01 B 3