I have a few hundred GBs of data in a MySQL database that I would like to archive in a low-cost cloud storage. At the same time, I would still like the data to be easily accessible and retrieve using API. I am looking for a technology-independent solution (not tied to any particular database engine).
The frequency of retrieval is expected to be very low but I would like to keep the "cost" (that is the effort) of retrieval to be low as well. I can live with a higher latency to retrieve the data.
I was thinking of using Spark/Databricks (to provide the structured API interface) with long term storage solutions such as Azure Data Lake Storage Gen2 (to provide the low cost storage).
Is this the optimal solution or are there better alternatives?
Thanks.
CodePudding user response:
Yes, Azure Data Lake Storage Gen2 (ADLS2) is the best cloud service to store the data in archive with low cost.
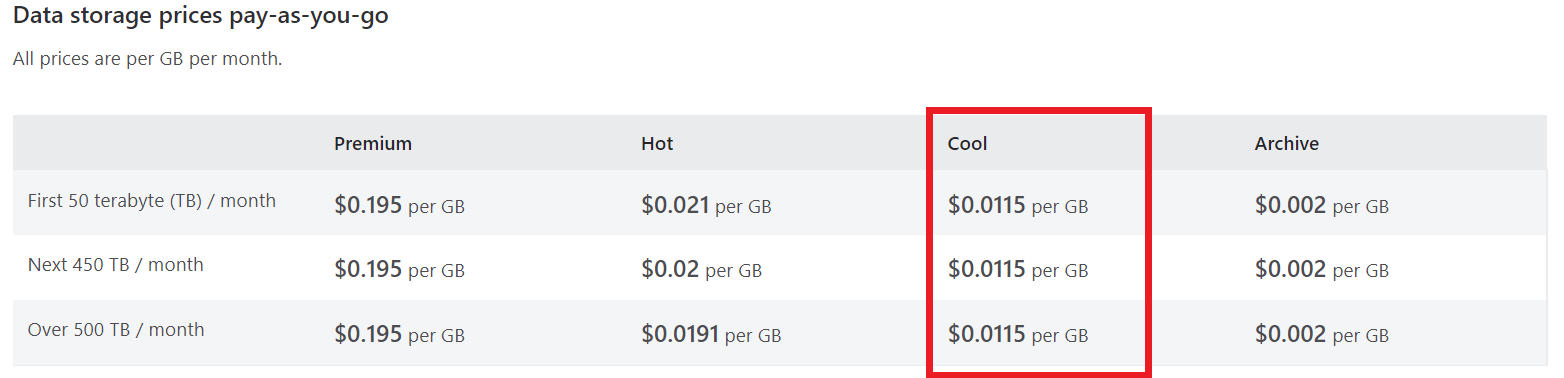
Check the detailed pricing 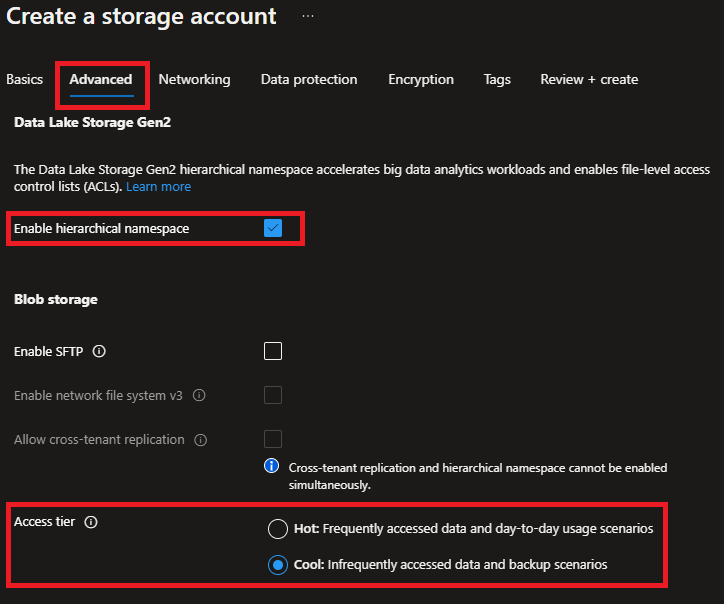
You can easily authenticate and access Azure Data Lake Storage Gen2 (ADLS Gen2) storage accounts using an Azure storage account access key. Apache Spark provide multiple APIs (RDD, DataFrame, DataSet) which can help you to access and transform the data as per your requirement.
Refer to learn more about APIs: Databricks with ADLS Gen2, RDDs vs DataFrames and Datasets
Note: To retrieve the data you must change the ADLS access tier to Hot.