i am trying to make some clasification on a data, i have my X and y and they look like this
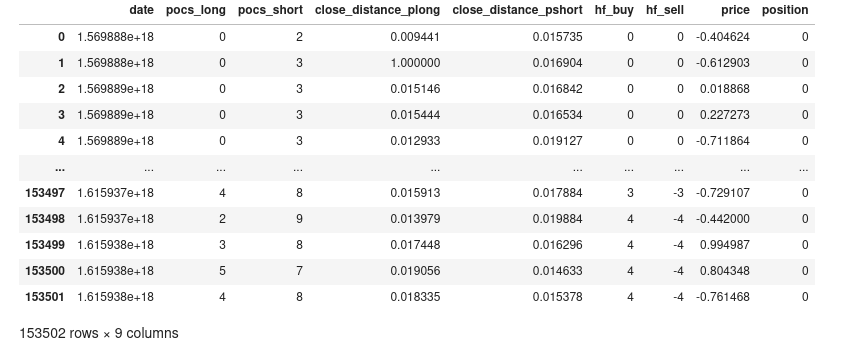
this is the X info
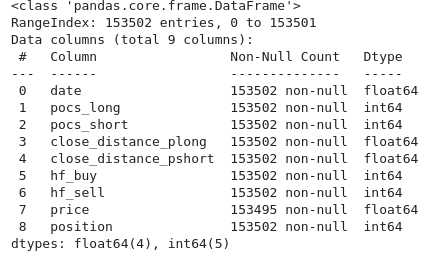
in the y i have a pandas dataframe of 1 col, which can contain an 1, 0 or -1, also the column position in X can be 1,0,-1
so i try to preprocess the data like this
X_train, y_train = X.iloc[0:107452], y.iloc[0:107452]
X_test, y_test = X.iloc[107452:len(X)], y.iloc[107452:len(y)]
y_train = tf.keras.utils.to_categorical(y_train)
y_test = tf.keras.utils.to_categorical(y_test)
X_train= np.asarray(X_train).astype('float32')
X_train=X_train.reshape(-1, 107452, 9)
y_train= np.asarray(y_train).astype('float32')
y_train=y_train.reshape(-1, 107452, 1)
X_test = np.asarray(X_test).astype('float32')
X_test=X_test.reshape(-1, 46050, 9)
y_test= np.asarray(y_test).astype('float32')
y_test=y_test.reshape(-1, 46050, 1)
to make the y a categorical. so the shape of the X(train and test) and y are
X_train shape: (1, 107452, 9), y_train shape: (2, 107452, 1)
X_test shape: (1, 46050, 9), y_test shape: (2, 46050, 1)
for the model i used this
model = keras.Sequential()
model.add(keras.layers.LSTM(250, input_shape=(X_train.shape[1], X_train.shape[2])))
model.add(keras.layers.Dropout(0.2))
model.add(keras.layers.Dense(3,activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam')
model.summary()
history = model.fit(
X_train, y_train,
epochs=32,
batch_size=32,
shuffle=False
)
but i get the next error
ValueError: Data cardinality is ambiguous:
x sizes: 1
y sizes: 2
Make sure all arrays contain the same number of samples.
hope any of you can help me to figure out how to make it work, in advance thanks
CodePudding user response:
After this line:
X_train, y_train = X.iloc[0:107452], y.iloc[0:107452]
X_train= np.asarray(X_train).astype('float32')
Try running:
y_train = tf.keras.utils.to_categorical(y_train, 3) # 3 classes
X_train = tf.expand_dims(X_train, axis=-1)
And it should work. The same applies to your test data.