I have a table with a field A where each entry is a fixed length array A of integers (say length=1000). I want to know how to convert it into 1000 columns, with column name given by index_i, for i=0,1,2,...,999, and each element is the corresponding integer. I can have it done by something like
A[OFFSET(0)] as index_0,
A[OFFSET(1)] as index_1
A[OFFSET(2)] as index_2,
A[OFFSET(3)] as index_3,
A[OFFSET(4)] as index_4,
...
A[OFFSET(999)] as index_999,
I want to know what would be an elegant way of doing this. thanks!
CodePudding user response:
Consider below approach
execute immediate ( select '''
select * except(id) from (
select to_json_string(A) id, * except(A)
from your_table, unnest(A) value with offset
)
pivot (any_value(value) index for offset in ('''
|| (select string_agg('' || val order by offset) from unnest(generate_array(0,999)) val with offset) || '))'
)
If to apply to dummy data like below (with 10 instead of 1000 elements)
select [10,11,12,13,14,15,16,17,18,19] as A union all
select [20,21,22,23,24,25,26,27,28,29] as A union all
select [30,31,32,33,34,35,36,37,38,39] as A
the output is
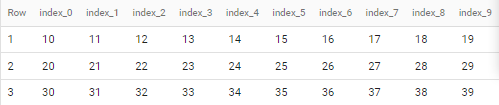
CodePudding user response:
The first thing to say is that, sadly, this is going to be much more complicated than most people expect. It can be conceptually easier to pass the values into a scripting language (e.g. Python) and work there, but clearly keeping things inside BigQuery is going to be much more performant. So here is an approach.
Cross-joining to turn array fields into long-format tables
I think the first thing you're going to want to do is get the values out of the arrays and into rows.
Typically in BigQuery this is accomplished using CROSS JOIN. The syntax is a tad unintuitive:
WITH raw AS (
SELECT "A" AS name, [1,2,3,4,5] AS a
UNION ALL
SELECT "B" AS name, [5,4,3,2,1] AS a
),
long_format AS (
SELECT name, vals
FROM raw
CROSS JOIN UNNEST(raw.a) AS vals
)
SELECT * FROM long_format
UNNEST(raw.a) is taking those arrays of values and turning each array into a set of (five) rows, every single one of which is then joined to the corresponding value of name (the definition of a CROSS JOIN). In this way we can 'unwrap' a table with an array field.
This will yields results like
name | vals
-------------
A | 1
A | 2
A | 3
A | 4
A | 5
B | 5
B | 4
B | 3
B | 2
B | 1
Confusingly, there is a shorthand for this syntax in which CROSS JOIN is replaced with a simple comma:
WITH raw AS (
SELECT "A" AS name, [1,2,3,4,5] AS a
UNION ALL
SELECT "B" AS name, [5,4,3,2,1] AS a
),
long_format AS (
SELECT name, vals
FROM raw, UNNEST(raw.a) AS vals
)
SELECT * FROM long_format
This is more compact but may be confusing if you haven't seen it before.
Typically this is where we stop. We have a long-format table, created without any requirement that the original arrays all had the same length. What you're asking for is harder to produce - you want a wide-format table containing the same information (relying on the fact that each array was the same length.
Pivot tables in BigQuery
The good news is that BigQuery now has a PIVOT function! That makes this kind of operation possible, albeit non-trivial:
WITH raw AS (
SELECT "A" AS name, [1,2,3,4,5] AS a
UNION ALL
SELECT "B" AS name, [5,4,3,2,1] AS a
),
long_format AS (
SELECT name, vals, offset
FROM raw, UNNEST(raw.a) AS vals WITH OFFSET
)
SELECT *
FROM long_format PIVOT(
ANY_VALUE(vals) AS vals
FOR offset IN (0,1,2,3,4)
)
This makes use of WITH OFFSET to generate an extra offset column (so that we know which order the values in the array originally had).
Also, in general pivoting requires us to aggregate the values returned in each cell. But here we expect exactly one value for each combination of name and offset, so we simply use the aggregation function ANY_VALUE, which non-deterministically selects a value from the group you're aggregating over. Since, in this case, each group has exactly one value, that's the value retrieved.
The query yields results like:
name vals_0 vals_1 vals_2 vals_3 vals_4
----------------------------------------------
A 1 2 3 4 5
B 5 4 3 2 1
This is starting to look pretty good, but we have a fundamental issue, in that the column names are still hard-coded. You wanted them generated dynamically.
Unfortunately expressions for the pivot column values aren't something PIVOT can accept out-of-the-box. Note that BigQuery has no way to know that your long-format table will resolve neatly to a fixed number of columns (it relies on offset having the values 0-4 for each and every set of records).
Dynamically building/executing the pivot
And yet, there is a way. We will have to leave behind the comfort of standard SQL and move into the realm of BigQuery Procedural Language.
What we must do is use the expression EXECUTE IMMEDIATE, which allows us to dynamically construct and execute a standard SQL query!
(as an aside, I bet you - OP or future searchers - weren't expecting this rabbit hole...)
This is, of course, inelegant to say the least. But here is the above toy example, implemented using EXECUTE IMMEDIATE. The trick is that the executed query is defined as a string, so we just have to use an expression to inject the full range of values you want into this string.
Recall that || can be used as a string concatenation operator.
EXECUTE IMMEDIATE """
WITH raw AS (
SELECT "A" AS name, [1,2,3,4,5] AS a
UNION ALL
SELECT "B" AS name, [5,4,3,2,1] AS a
),
long_format AS (
SELECT name, vals, offset
FROM raw, UNNEST(raw.a) AS vals WITH OFFSET
)
SELECT *
FROM long_format PIVOT(
ANY_VALUE(vals) AS vals
FOR offset IN ("""
|| (SELECT STRING_AGG(CAST(x AS STRING)) FROM UNNEST(GENERATE_ARRAY(0,4)) AS x)
|| """
)
)
"""
Ouch. I've tried to make that as readable as possible. Near the bottom there is an expression that generates the list of column suffices (pivoted values of offset):
(SELECT STRING_AGG(CAST(x AS STRING)) FROM UNNEST(GENERATE_ARRAY(0,4)) AS x)
This generates the string "0,1,2,3,4" which is then concatenated to give us ...FOR offset IN (0,1,2,3,4)... in our final query (as in the hard-coded example before).
REALLY dynamically executing the pivot
It hasn't escaped my notice that this is still technically insisting on your knowing up-front how long those arrays are! It's a big improvement (in the narrow sense of avoiding painful repetitive code) to use GENERATE_ARRAY(0,4), but it's not quite what was requested.
Unfortunately, I can't provide a working toy example, but I can tell you how to do it. You would simply replace the pivot values expression with
(SELECT STRING_AGG(DISTINCT CAST(offset AS STRING)) FROM long_format)
But doing this in the example above won't work, because long_format is a Common Table Expression that is only defined inside the EXECUTE IMMEDIATE block. The statement in that block won't be executed until after building it, so at build-time long_format has yet to be defined.
Yet all is not lost. This will work just fine:
SELECT *
FROM d.long_format PIVOT(
ANY_VALUE(vals) AS vals
FOR offset IN ("""
|| (SELECT STRING_AGG(DISTINCT CAST(offset AS STRING)) FROM d.long_format)
|| """
)
)
... provided you first define a BigQuery VIEW (for example) called long_format (or, better, some more expressive name) in a dataset d. That way, both the job that builds the query and the job that runs it will have access to the values.
If successful, you should see both jobs execute and succeed. You should then click 'VIEW RESULTS' on the job that ran the query.
As a final aside, this assumes you are working from the BigQuery console. If you're instead working from a scripting language, that gives you plenty of options to either load and manipulate the data, or build the query in your scripting language rather than massaging BigQuery into doing it for you.