I have this table in MySQL 5.6.36-82.0:
| id | COD_A | COD_B |
|---|---|---|
| ... | ... | ... |
| 205 | 6 | NULL |
| 205 | 6 | 2 |
| 442 | 2 | 7 |
| 442 | 7 | NULL |
| ... | ... | ... |
Expected output:
| id | COD_A | COD_B |
|---|---|---|
| ... | ... | ... |
| 205 | 6 | 2 |
| 442 | 2 | 7 |
| 442 | 7 | NULL |
| ... | ... | ... |
In this example I expect to return a select without the row | 205 | 6 | NULL |
CodePudding user response:
select id, cod_a, max(cod_b) COD_B from t group by cod_a order by id asc
Result :
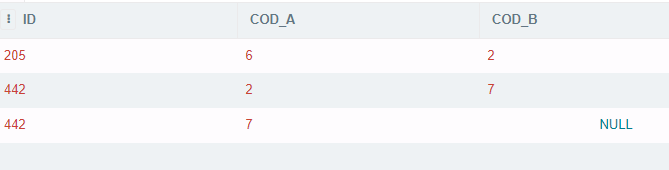
CodePudding user response:
SELECT * FROM example WHERE id = 205 AND Col_b <> "NULL" OR id <> 205;
This line returns the table you want, there might be a better way to do it but it works.
In general it's not a good idea to have a repeated value in your "id" column since it's your identifier after all.
CodePudding user response:
You can do:
select * from t where id <> 205 or cod_b is not null
Incidentally, MySQL 5 is reaching end of life next year. Maybe it's worth considering an upgrade.
CodePudding user response:
We can use group by id,COD_A having count(*) >1 to get those rows with duplicate id and COD_A combination. Meanwhile, those lines must have COD_B is null. Finally, exclude the rows matching the above conditions using NOT EXISTS to get the desired rows from the main table:
select * from tb t where not exists
(
select id,COD_A from tb where id=t.id and COD_A=t.COD_A group by id,COD_A having count(*) >1
and
COD_B is null
);