How can I create a cross table in R (RStudio), where I count occurrences.
I have this sample input:
Technology <- c("A", "A", "B", "C", "C", "C")
Development <- c(1, 0, 1, 1, 1, 1)
Production <- c(1, 1, 0, 0, 0, 1)
Sales <- c(0, 0, 1, 1, 0, 1)
DF <- data.frame(Technology, Development, Production, Sales)
I want to know in which domain which technology is used most often.
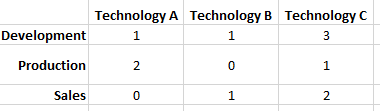
The result should look like in the picture.
CodePudding user response:
These problems are many times a data format problem and the solution is to reshape from wide to long format first, see this question.
Here is a base R solution with reshape and cross tabulation with xtabs.
Technology <- c("A", "A", "B", "C", "C", "C")
Development <- c(1, 0, 1, 1, 1, 1)
Production <- c(1, 1, 0, 0, 0, 1)
Sales <- c(0, 0, 1, 1, 0, 1)
DF <- data.frame(Technology, Development, Production, Sales)
reshape(
DF,
direction = "long",
varying = list(names(DF[-1])),
v.names = "Active",
times = names(DF[-1]),
timevar = "Phase"
) |>
(\(x) xtabs(Active ~ Phase Technology, x))()
#> Technology
#> Phase A B C
#> Development 1 1 3
#> Production 2 0 1
#> Sales 0 1 2
Created on 2022-04-18 by the reprex package (v2.0.1)
And a tidyverse solution.
suppressPackageStartupMessages({
library(magrittr)
library(tidyr)
})
DF %>%
pivot_longer(-Technology) %>%
xtabs(value ~ name Technology, .)
#> Technology
#> name A B C
#> Development 1 1 3
#> Production 2 0 1
#> Sales 0 1 2
Created on 2022-04-18 by the reprex package (v2.0.1)
CodePudding user response:
Here is a tidyverse approach, to get your desired output:
- We group by Technology to summarise with
across - then we prepare the rownames with
pasteand applycolumn_to_rownamesfromtibble - finally we could transform with
t()
library(dplyr)
library(tibble)
DF %>%
group_by(Technology) %>%
summarise(across(c(Development, Production, Sales), sum)) %>%
mutate(Technology = paste("Technology", Technology, sep = " ")) %>%
column_to_rownames("Technology") %>%
t()
Technology A Technology B Technology C
Development 1 1 3
Production 2 0 1
Sales 0 1 2