I am using a table which is partitioned by load_date column and is weekly optimized with delta optimize command as source dataset for my use case.
The table schema is as shown below:
----------------- -------------------- ------------ --------- -------- ---------------
| ID| readout_id|readout_date|load_date|item_txt| item_value_txt|
----------------- -------------------- ------------ --------- -------- ---------------
Later this table will be pivoted on columns item_txt and item_value_txt and many operations are applied using multiple window functions as shown below:
val windowSpec = Window.partitionBy("id","readout_date")
val windowSpec1 = Window.partitionBy("id","readout_date").orderBy(col("readout_id") desc)
val windowSpec2 = Window.partitionBy("id").orderBy("readout_date")
val windowSpec3 = Window.partitionBy("id").orderBy("readout_date").rowsBetween(Window.unboundedPreceding, Window.currentRow)
val windowSpec4 = Window.partitionBy("id").orderBy("readout_date").rowsBetween(Window.unboundedPreceding, Window.currentRow-1)
These window functions are used to achieve multiple logic on the data. Even there are few joins used to process the data.
The final table is partitioned with readout_date and id and could see the performance is very poor as it take much time for 100 ids and 100 readout_date
If I am not partitioning the final table I am getting the below error.
Job aborted due to stage failure: Total size of serialized results of 129 tasks (4.0 GiB) is bigger than spark.driver.maxResultSize 4.0 GiB.
The expected count of id in production is billions and I expect much more throttling and performance issues while processing with complete data.
Below provided the cluster configuration and utilization metrics.
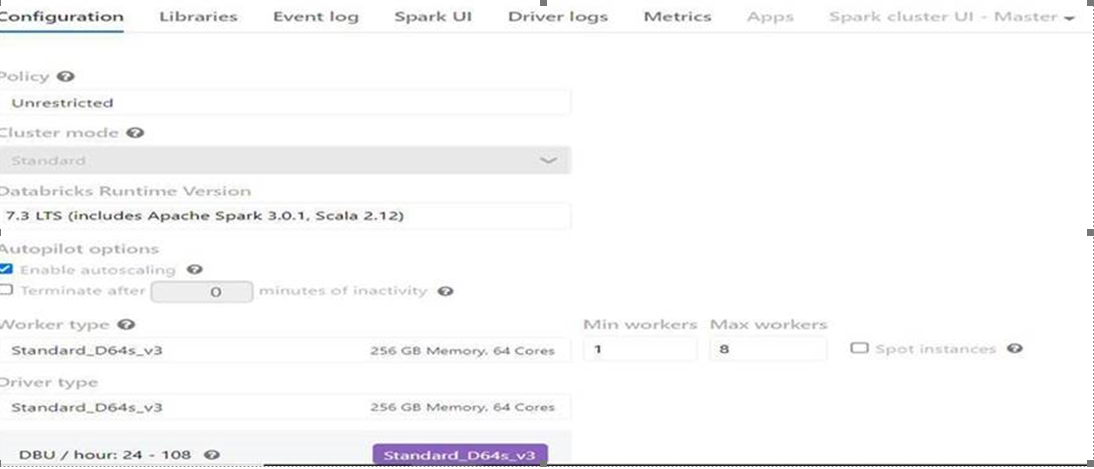
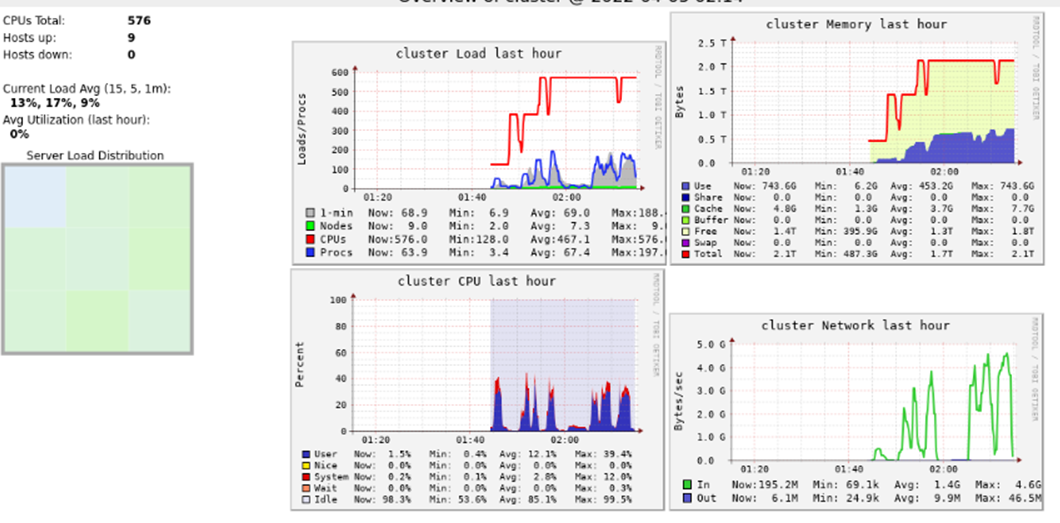
Please let me know if anything is wrong while doing repartitioning, any methods to improve cluster utilization, to improve performance...
Any leads Appreciated!
CodePudding user response:
spark.driver.maxResultSize is just a setting you can increase it. BUT it's set at 4Gigs to warn you you are doing bad things and you should optimize your work. You are doing the correct thing asking for help to optimize.
The first thing I suggest if you care about performance get rid of the windows. The first 3 windows you use could be achieved using Groupby and this will perform better. The last two windows are definitely harder to reframe as a group by, but with some reframing of the problem you might be able to do it. The trick could be to use multiple queries instead of one. And you might think that would perform worse but i'm here to tell you if you can avoid using a window you will get better performance almost every time. Windows aren't bad things, they are a tool to be used but they do not perform well on unbounded data. (Can you do anything as an intermediate step to reduce the data the window needs to examine?) Or can you use aggregate functions to complete the work without having to use a window? You should explore your options.
CodePudding user response:
Given your other answers, you should be grouping by ID not windowing by Id. And likely using aggregates(sum) by week of year/month. This would likely give you really speedy performance with the loss of some granularity. This would give you enough insight to decide to look into something deeper... or not.
If you wanted more accuracy, I'd suggest using: Converting your null's to 0's.
val windowSpec1 = Window.partitionBy("id").orderBy(col("readout_date") asc) // asc is important as it flips the relationship so that it groups the previous nulls
Then create a running total on the SIG_XX VAL or whatever signal you want to look into. Call the new column 'null-partitions'.
This will effectively allow you to group the numbers(by null-partitions) and you can then run aggregate functions using group by to complete your calculations. Window and group by can do the same thing, windows just more expensive in how it moves data, slowing things down. Group by uses a more of the cluster to do the work and speeds up the process.