I have a Dataset under this form
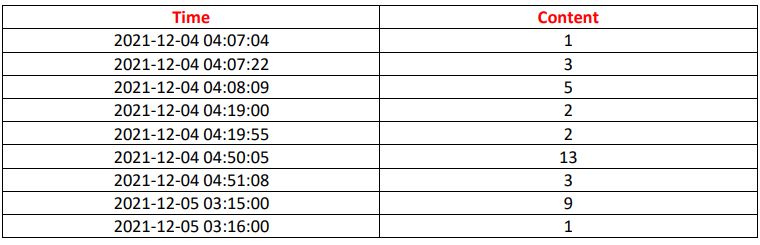
I want to split the data set by making a windowing which includes the lines that happen every 2 minutes, then i m going to include the result in another data set which will be under this form
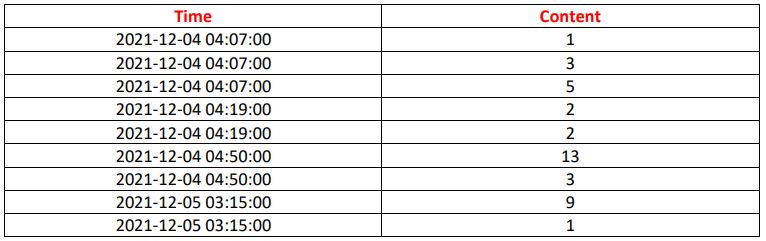
i'm asking if anyone can offer me a hand to speed up my work?
CodePudding user response:
Here is a random dataframe, df:
df:
Content
Date
2021-12-04 04:07:04 6
2021-12-04 04:07:20 1
2021-12-04 04:08:04 4
2021-12-04 04:09:04 12
2021-12-04 04:12:04 4
2021-12-04 04:15:04 8
2021-12-04 04:15:04 10
2021-12-04 04:16:04 4
2021-12-04 04:17:04 6
2021-12-04 04:17:24 3
Now, I will use pd.Grouper for '2Min' frequency and apply(list)
df_out= df.groupby(pd.Grouper(freq='2Min'))['Content'].apply(list).
df_out:
Date
2021-12-04 04:06:00 [6, 1]
2021-12-04 04:08:00 [4, 12]
2021-12-04 04:10:00 []
2021-12-04 04:12:00 [4]
2021-12-04 04:14:00 [8, 10]
2021-12-04 04:16:00 [4, 6, 3]
if you want the 2nd column as a list then use .tolist():
list=df_out.tolist()
list:
[[6, 1], [4, 12], [], [4], [8, 10], [4, 6, 3]]
to get each element use df_out[i] # i=0,1,2, etc
if you want to convert it into a data frame then use pd.DataFrame(df_out)
Remember if you are reading the text file from a csv or whatever file you will have to convert your df index to datetime index using:
df.index = pd.to_datetime(df.index)
Entire code for a test csv file:
import pandas as pd
df=pd.read_csv(r'D:\python\test.txt', sep=',').set_index('Date')
df.index = pd.to_datetime(df.index)
df_out= df.groupby(pd.Grouper(freq='2Min'))['Content'].apply(list)
If you don't know how to create a sample df, here I put another example:
import pandas as pd
import numpy as np
np.random.seed(0)
# create an array of 10 dates starting at '2021-12-04', one per minute
rng = pd.date_range('2021-12-04 04:07:04', periods=10, freq='T')
df_random = pd.DataFrame({ 'Date': rng, 'Content': np.random.randint(1,13,10) }).set_index('Date')
df_random_out= df_random.groupby(pd.Grouper(freq='2Min'))['Content'].apply(list)
df_random:
Content
Date
2021-12-04 04:07:04 6
2021-12-04 04:08:04 1
2021-12-04 04:09:04 4
2021-12-04 04:10:04 12
2021-12-04 04:11:04 4
2021-12-04 04:12:04 8
2021-12-04 04:13:04 10
2021-12-04 04:14:04 4
2021-12-04 04:15:04 6
2021-12-04 04:16:04 3
df_random_out:
Date
2021-12-04 04:06:00 [6]
2021-12-04 04:08:00 [1, 4]
2021-12-04 04:10:00 [12, 4]
2021-12-04 04:12:00 [8, 10]
2021-12-04 04:14:00 [4, 6]
2021-12-04 04:16:00 [3]
N.B: Please explain clearly what you want to do with your results so that I can answer accordingly.
CodePudding user response:
It took me some time and I posted an answer but deleted as I realised it was different from the expected result...also took a piece of @Shuvashish - the apply(list). But anyways..this should give you the expected result:
df['Time']=pd.to_datetime(df['Time'])
df.set_index('Time',inplace=True)
df2=pd.DataFrame(df.groupby(pd.Grouper(freq='2Min',origin=df.index[0].floor('Min')))['Content'].apply(list).explode())
df2[df2.Content.notna()].reset_index()
Shuvashish already showed the pd.Grouper - I only exploded the results and set the origin to be the first time value 'floored' to the minute - btw in your expected table ,there shouldn't be 04:50:00 time as we started binning every 2 minutes from an odd number 04:07:00