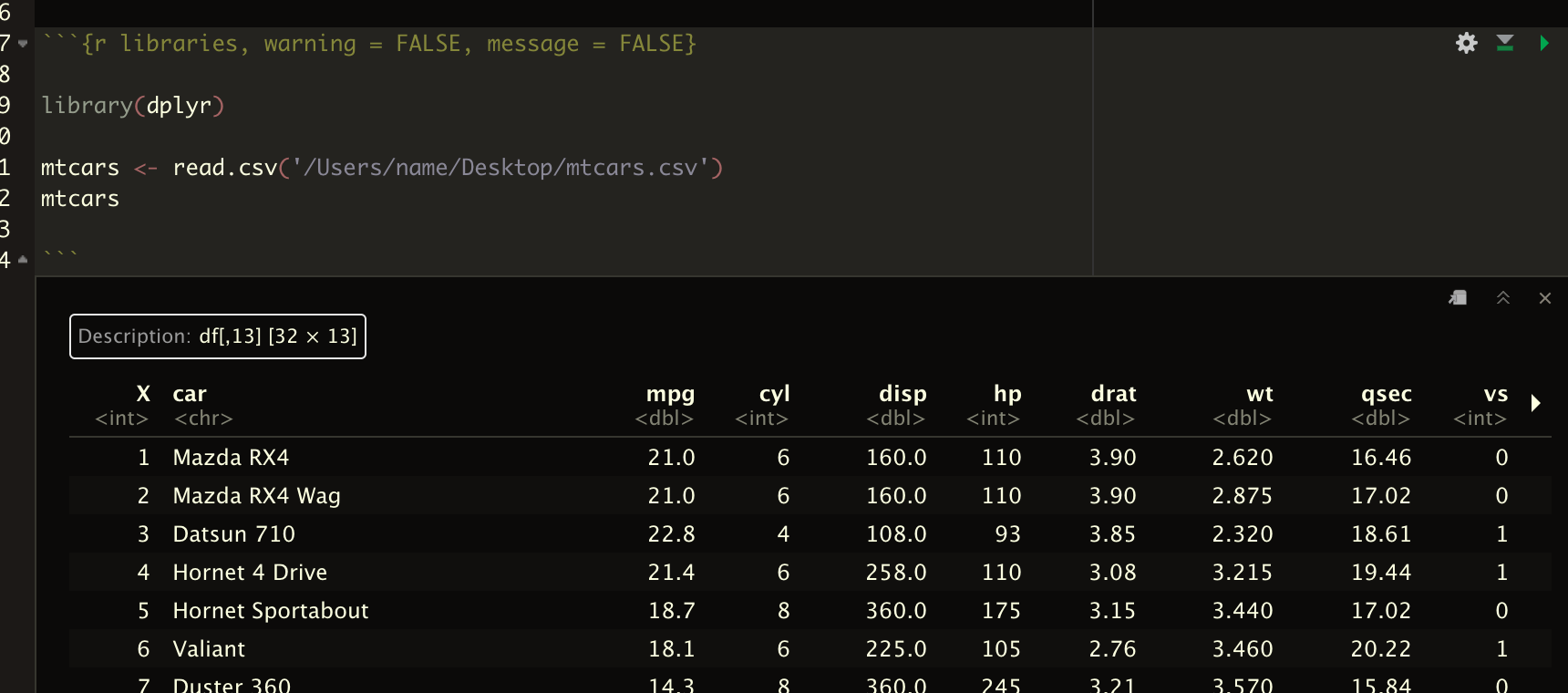
I'm using RStudio and reading a dataframe into RStudio using the R language by using the read.csv function and I don't have any problem.
Here is the output of R's dput function so you can see the datarame. I can't do an equivalent version for python because I'm not getting the correct version in RStudio.
structure(list(X = 1:32, car = c("Mazda RX4", "Mazda RX4 Wag",
"Datsun 710", "Hornet 4 Drive", "Hornet Sportabout", "Valiant",
"Duster 360", "Merc 240D", "Merc 230", "Merc 280", "Merc 280C",
"Merc 450SE", "Merc 450SL", "Merc 450SLC", "Cadillac Fleetwood",
"Lincoln Continental", "Chrysler Imperial", "Fiat 128", "Honda Civic",
"Toyota Corolla", "Toyota Corona", "Dodge Challenger", "AMC Javelin",
"Camaro Z28", "Pontiac Firebird", "Fiat X1-9", "Porsche 914-2",
"Lotus Europa", "Ford Pantera L", "Ferrari Dino", "Maserati Bora",
"Volvo 142E"), mpg = c(21, 21, 22.8, 21.4, 18.7, 18.1, 14.3,
24.4, 22.8, 19.2, 17.8, 16.4, 17.3, 15.2, 10.4, 10.4, 14.7, 32.4,
30.4, 33.9, 21.5, 15.5, 15.2, 13.3, 19.2, 27.3, 26, 30.4, 15.8,
19.7, 15, 21.4), cyl = c(6L, 6L, 4L, 6L, 8L, 6L, 8L, 4L, 4L,
6L, 6L, 8L, 8L, 8L, 8L, 8L, 8L, 4L, 4L, 4L, 4L, 8L, 8L, 8L, 8L,
4L, 4L, 4L, 8L, 6L, 8L, 4L), disp = c(160, 160, 108, 258, 360,
225, 360, 146.7, 140.8, 167.6, 167.6, 275.8, 275.8, 275.8, 472,
460, 440, 78.7, 75.7, 71.1, 120.1, 318, 304, 350, 400, 79, 120.3,
95.1, 351, 145, 301, 121), hp = c(110L, 110L, 93L, 110L, 175L,
105L, 245L, 62L, 95L, 123L, 123L, 180L, 180L, 180L, 205L, 215L,
230L, 66L, 52L, 65L, 97L, 150L, 150L, 245L, 175L, 66L, 91L, 113L,
264L, 175L, 335L, 109L), drat = c(3.9, 3.9, 3.85, 3.08, 3.15,
2.76, 3.21, 3.69, 3.92, 3.92, 3.92, 3.07, 3.07, 3.07, 2.93, 3,
3.23, 4.08, 4.93, 4.22, 3.7, 2.76, 3.15, 3.73, 3.08, 4.08, 4.43,
3.77, 4.22, 3.62, 3.54, 4.11), wt = c(2.62, 2.875, 2.32, 3.215,
3.44, 3.46, 3.57, 3.19, 3.15, 3.44, 3.44, 4.07, 3.73, 3.78, 5.25,
5.424, 5.345, 2.2, 1.615, 1.835, 2.465, 3.52, 3.435, 3.84, 3.845,
1.935, 2.14, 1.513, 3.17, 2.77, 3.57, 2.78), qsec = c(16.46,
17.02, 18.61, 19.44, 17.02, 20.22, 15.84, 20, 22.9, 18.3, 18.9,
17.4, 17.6, 18, 17.98, 17.82, 17.42, 19.47, 18.52, 19.9, 20.01,
16.87, 17.3, 15.41, 17.05, 18.9, 16.7, 16.9, 14.5, 15.5, 14.6,
18.6), vs = c(0L, 0L, 1L, 1L, 0L, 1L, 0L, 1L, 1L, 1L, 1L, 0L,
0L, 0L, 0L, 0L, 0L, 1L, 1L, 1L, 1L, 0L, 0L, 0L, 0L, 1L, 0L, 1L,
0L, 0L, 0L, 1L), am = c(1L, 1L, 1L, 0L, 0L, 0L, 0L, 0L, 0L, 0L,
0L, 0L, 0L, 0L, 0L, 0L, 0L, 1L, 1L, 1L, 0L, 0L, 0L, 0L, 0L, 1L,
1L, 1L, 1L, 1L, 1L, 1L), gear = c(4L, 4L, 4L, 3L, 3L, 3L, 3L,
4L, 4L, 4L, 4L, 3L, 3L, 3L, 3L, 3L, 3L, 4L, 4L, 4L, 3L, 3L, 3L,
3L, 3L, 4L, 5L, 5L, 5L, 5L, 5L, 4L), carb = c(4L, 4L, 1L, 1L,
2L, 1L, 4L, 2L, 2L, 4L, 4L, 3L, 3L, 3L, 4L, 4L, 4L, 1L, 2L, 1L,
1L, 2L, 2L, 4L, 2L, 1L, 2L, 2L, 4L, 6L, 8L, 2L)), class = "data.frame", row.names = c(NA,
-32L))
And here is an image of the code and the dataframe in the RStudio console.
Now I'm reading the same csv into RStudio using python, except this one doesn't work so well. A few of the variables like the wt variable are missing, for example. Also, it created an extra column on the left. I thought maybe this is because the wt variable is a dbl but this can't be the reason because mpg is also a double.
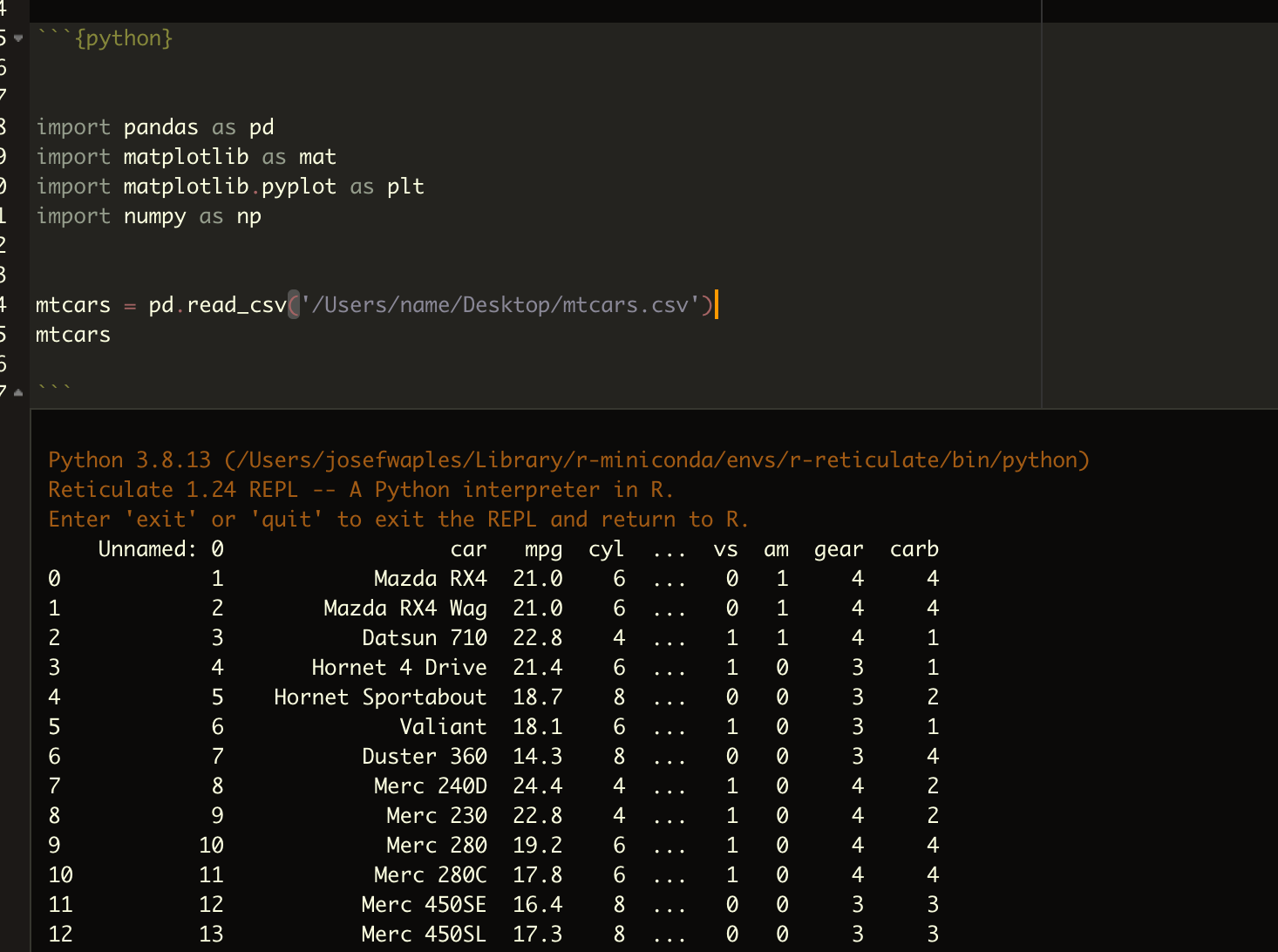
What am I doing wrong in pd.read_csv that the mtcars dataframe is not read correctly?
CodePudding user response:
Your Python code is not wrong. It is just the dataframe being too "wide" with too many columns and it cannot display all columns. That's why there is a '...' between cyl and vs.
To solve this, see How do I expand the output display to see more columns of a Pandas DataFrame?
I think you come from RStudio and it probably bothers you that the dataframe is not fully shown. Personally, I am already used to it when most of the time I am clear about what data columns I currently have.
For the Unnamed: 0 column, that happens probably because last time when you write the dataframe to csv, you also included the unwanted index. Your mtcars.csv probably look like this:
,car,mpg,...
1,Mazda RX4,21.0,...
2,Mazda RX4 Wag,21.0,...
But it is better to be
car,mpg,...
Mazda RX4,21.0,...
Mazda RX4 Wag,21.0,...
because the index you saved is probably meaningless.
You either (1) don't write the index into csv next time (I don't know if you are working with R or Python), or (2) write pd.read_csv('mtcars.csv', index=0) so that the zeroth column in your csv is automatically parsed as index.
CodePudding user response:
the data was read successfully. If you say it for the dots in the display is because by default in python pandas only displays a few columns, you can change it with
# it will show all columns
import pandas as pd
pd.set_option("display.max_columns", None)
And for the column 'Unnamed: 0', that's an index which was saved by default without a name, you use it as index instead of as a column with the following parameter:
pd.read_csv('mtcars.csv', index=0)
If you want to ignore it meanwhile reading you can use:
pd.read_csv('mtcars.csv', index_col=False)