I want to save a list of object in the dataframe. I'm wondering if it works in R programming. Here's several fake data about statistic mid-term score in different class:
name <- c('John','Mary','George','Sam','Bruce','Kiki','Jossef','Chen','Bob','May')
score_sample <- sample(1:100, 10, replace = TRUE)
eco_1A <- data.frame(name = name , score = score_sample)
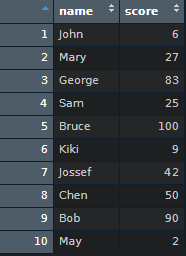
I want to know which student pass the test, and it would look like this:
class <- c('eco_1A','eco_1B','soc_1A','BA_1A','BA_1B')
pass_name_sheet <- c('Mary,Sam','Bruce','Jack','Kiki,Cheng,Bob','Jossef' )
all_score <- data.frame(class = class ,pass_name_sheet = pass_name_sheet)
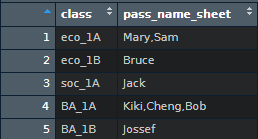
I want to know each student's name who pass the test for each class.
How should I do?
CodePudding user response:
It looks like you're trying to filter a dataset by students that passed. Assuming your dataset has three columns:
'class' - the class the student enrolled in. 'pass_name_sheet' - the name of the student. 'all_score' - the score of the student.
Suppose the passing marks are 70, you can find the students who passed with this command:
passed_students <- dataset[which(dataset$all_score >= 70),]$pass_name_sheet
This command takes only the observations where the score is equal to or above 70, and takes the names of those students. In case you want to get all the columns for those students, you can simply remove '$pass_name_sheet' from the end of the command.
CodePudding user response:
The dplyr worflow is:
library(dplyr)
mget(class[class %in% ls()]) %>%
bind_rows(.id = "class") %>%
filter(score >= 60) %>%
group_by(class) %>%
summarise(pass_name_sheet = toString(name))
# # A tibble: 2 x 2
# class pass_name_sheet
# <chr> <chr>
# 1 BA_1A Mary, Chen, May
# 2 eco_1A John, George, Sam, Jossef
If you're going to do further analysis on these names, storing them as a list-column is recommended, i.e.
... %>%
summarise(pass_name_sheet = list(name))
# # A tibble: 2 x 2
# class pass_name_sheet
# <chr> <list>
# 1 BA_1A <chr [3]>
# 2 eco_1A <chr [4]>
Data
class <- c('eco_1A', 'BA_1A')
BA_1A <- structure(list(name = c("John", "Mary", "George", "Sam", "Bruce",
"Kiki", "Jossef", "Chen", "Bob", "May"), score = c(11L, 82L, 1L, 8L, 37L,
43L, 6L, 93L, 9L, 84L)), class = "data.frame", row.names = c(NA, -10L))
eco_1A <- structure(list(name = c("John", "Mary", "George", "Sam", "Bruce",
"Kiki", "Jossef", "Chen", "Bob", "May"), score = c(82L, 32L, 61L, 94L, 58L,
25L, 64L, 5L, 15L, 48L)), class = "data.frame", row.names = c(NA, -10L))