I have code as below. My questions:
- why is it assigning week 1 to
2014-12-29and'2014-1-1'? Why it is not assigning week 53 to2014-12-29? - how could i assign week number that is continuously increasing? I
want
'2014-12-29','2015-1-1'to have week 53 and'2015-1-15'to have week 55 etc.
x=pd.DataFrame(data=['2014-1-1','2014-12-29','2015-1-1','2015-1-15'],columns=['date'])

x['week_number']=pd.DatetimeIndex(x['date']).week
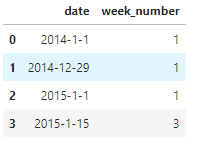
CodePudding user response:
As far as why the week number is 1 for 12/29/2014 -- see the question I linked to in the comments. For the second part of your question:
January 1, 2014 was a Wednesday. We can take the minimum date of your date column, get the day number and subtract from the difference:
Solution
# x["date"] = pd.to_datetime(x["date"]) # if not already a datetime column
min_date = x["date"].min() 1 # 1 because they're zero-indexed
x["weeks_from_start"] = ((x["date"].diff().dt.days.cumsum() - min_date) // 7 1).fillna(1).astype(int)
Output:
date weeks_from_start
0 2014-01-01 1
1 2014-12-29 52
2 2015-01-01 52
3 2015-01-15 54
Step by step
The first step is to convert the date column to the datetime type, if you haven't already:
In [3]: x.dtypes
Out[3]:
date object
dtype: object
In [4]: x["date"] = pd.to_datetime(x["date"])
In [5]: x
Out[5]:
date
0 2014-01-01
1 2014-12-29
2 2015-01-01
3 2015-01-15
In [6]: x.dtypes
Out[6]:
date datetime64[ns]
dtype: object
Next, we need to find the minimum of your date column and set that as the starting date day of the week number (adding 1 because the day number starts at 0):
In [7]: x["date"].min().day 1
Out[7]: 2
Next, use the built-in .diff() function to take the differences of adjacent rows:
In [8]: x["date"].diff()
Out[8]:
0 NaT
1 362 days
2 3 days
3 14 days
Name: date, dtype: timedelta64[ns]
Note that we get NaT ("not a time") for the first entry -- that's because the first row has nothing to compare to above it.
The way to interpret these values is that row 1 is 362 days after row 0, and row 2 is 3 days after row 1, etc.
If you take the cumulative sum and subtract the starting day number, you'll get the days since the starting date, in this case 2014-01-01, as if the Wednesday was day 0 of that first week (this is because when we calculate the number of weeks since that starting date, we need to compensate for the fact that Wednesday was the middle of that week):
In [9]: x["date"].diff().dt.days.cumsum() - min_date
Out[9]:
0 NaN
1 360.0
2 363.0
3 377.0
Name: date, dtype: float64
Now when we take the floor division by 7, we'll get the correct number of weeks since the starting date:
In [10]: (x["date"].diff().dt.days.cumsum() - 2) // 7 1
Out[10]:
0 NaN
1 52.0
2 52.0
3 54.0
Name: date, dtype: float64
Note that we add 1 because (I assume) you're counting from 1 -- i.e., 2014-01-01 is week 1 for you, and not week 0.
Finally, the .fillna is just to take care of that NaT (which turned into a NaN when we started doing arithmetic). You use .fillna(value) to fill NaNs with value:
In [11]: ((x["date"].diff().dt.days.cumsum() - 2) // 7 1).fillna(1)
Out[11]:
0 1.0
1 52.0
2 52.0
3 54.0
Name: date, dtype: float64
Finally use .astype() to convert the column to integers instead of floats.