I have a data frame that looks like this:

I want to create a matrix that will count the number of times each time per 'ID', 'col2' and 'col3' says a fruit value:
CodePudding user response:
One way (vectorized):
df = df.set_index('ID')
new_df = pd.DataFrame(np.sum(df.to_numpy()[:, None] == np.unique(df.to_numpy())[:, None], axis=2), index=df.index, columns=np.unique(df.to_numpy()))
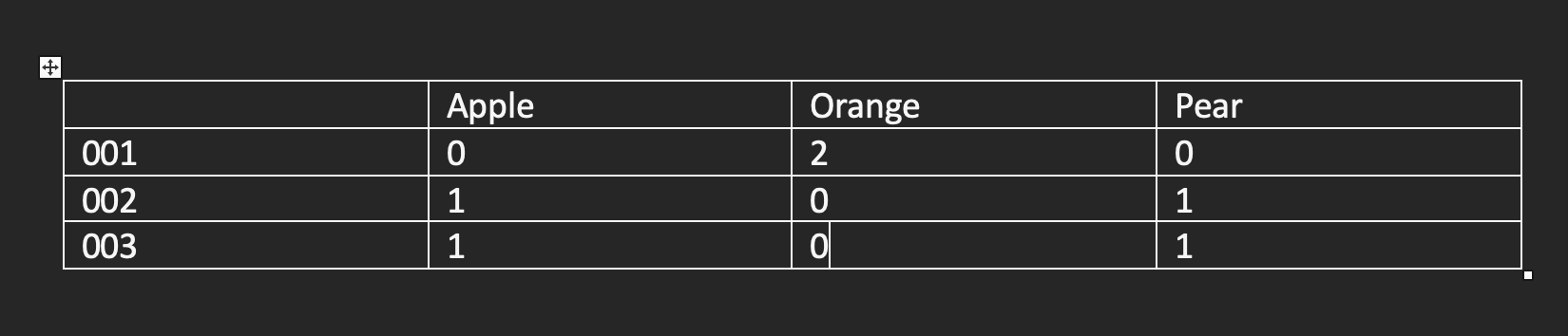
Output:
>>> new_df
Apple Orange Pear
ID
001 0 2 0
002 1 0 1
003 1 0 1
If you want to operate on only a subset of the columns:
subset = ['col2', 'col3']
new_df = pd.DataFrame(np.sum(df[subset].to_numpy()[:, None] == np.unique(df[subset].to_numpy())[:, None], axis=2), index=df.index, columns=np.unique(df[subset].to_numpy()))
CodePudding user response:
You can do:
df.set_index('ID', inplace=True)
dicts = [df.loc[idx].value_counts().to_dict() for idx in df.index]
df2 = pd.DataFrame(dicts, index=df.index).fillna(0).astype(int)
Output df2:
Orange Pear Apple
ID
001 2 0 0
002 0 1 1
003 0 1 1