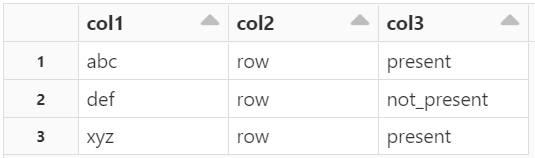
I have a PySpark dataframe with 50k records (dfa) and another with 40k records (dfb). In dfa, I want to create a new column tagging the 40k records in dfb with 'present' else 'not_present'.
I know pandas has syntax for this but I'm having trouble finding the PySpark syntax.
Input: dfa
| col1 | col2 |
|---|---|
| xyz | row |
| abc | row |
| def | row |
df2
| col1 | col2 |
|---|---|
| xyz | row |
| abc | row |
Expected Output:
df3
| col1 | col2 | col3 |
|---|---|---|
| xyz | row | present |
| abc | row | present |
| def | row | not_pre |
CodePudding user response:
df3 = df1.join(df2.select('col1', F.lit('present').alias('col3')).distinct(), 'col1', 'left')
df3 = df3.fillna('not_pre', 'col3')
Full example:
from pyspark.sql import functions as F
df1 = spark.createDataFrame(
[('xyz', 'row'),
('abc', 'row'),
('def', 'row')],
['col1', 'col2']
)
df2 = spark.createDataFrame(
[('xyz', 'row'),
('abc', 'row')],
['col1', 'col2']
)
df3 = df1.join(df2.select('col1', F.lit('present').alias('col3')).distinct(), 'col1', 'left')
df3 = df3.fillna('not_pre', 'col3')
df3.show()
# ---- ---- -------
# |col1|col2| col3|
# ---- ---- -------
# | xyz| row|present|
# | abc| row|present|
# | def| row|not_pre|
# ---- ---- -------
CodePudding user response:
you can try this as well if in case you want to check using combination of both the columns.
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('SparkByExamples.com').getOrCreate()
simpleData = [("xyz","row"), \
("abc","row"), \
("def","row")
]
columns= ["col1","col2"]
df1 = spark.createDataFrame(data = simpleData, schema = columns)
simpleData2 = [("xyz","row"), \
("abc","row")
]
columns2= ["col1","col2"]
df2 = spark.createDataFrame(data = simpleData2, schema = columns2)
joined = (df1.alias("df1").join(df2.alias("df2"),(col("df1.col1") == col("df2.col1")) & (col("df1.col2") == col("df2.col2")),"left"))
df = joined.select(col("df1.*"),col("df2.col1").isNotNull().cast("integer").alias("flag")).withColumn("col3",when(col('flag')==1,lit("present")).otherwise("not_present")).drop('flag')
display(df)