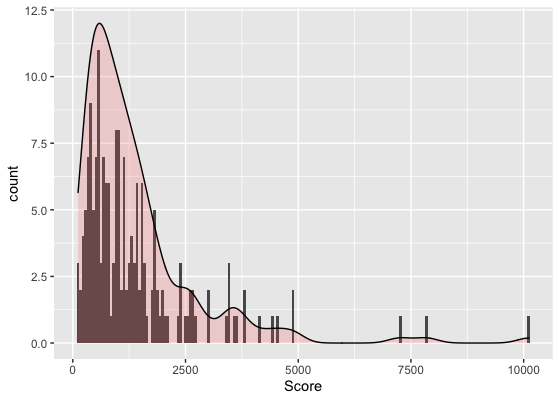
I would like to plot a density plot over counts histogram using following sample data:
However my density line was not readable in my plot. if I use ..ncount.., I can see it, but the plot is not the one I would prefer.
Plot1:
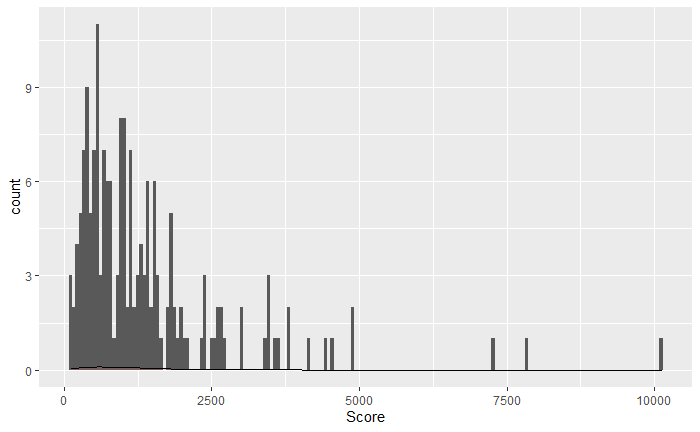
plot2:
I would like to have sth that looks like plot 2 but y can show the real counts. Is it a way to add density line over the real count? Maybe use 2nd y-axis? Any suggestion on this?
Also, I tried to plot it with different color for the Enroll, but did not find any different color in the plot. Did I code it wrong? or they are too small to detect?
structure(list(id = 1:177, Enroll = c(1, 0, 0, 1, 1, 1, 0, 0,
1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0,
0, 0, 1, 1, 1, 0, 1, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 1, 1, 0,
0, 1, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 0,
0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 1, 0, 1, 1,
0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0,
1, 0, 1, 0, 0, 1, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 1,
0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 1, 0, 1, 0, 1, 0, 0, 1, 0, 1,
0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 1, 1, 0, 0, 0, 1, 0, 0,
0), Score = c(4517.66371681416, 2402.58064516129, 1095.28571428571,
594.179372197309, 2988.72289156626, 2666.30630630631, 392, 235.117647058824,
1404.66265060241, 1419.29770992366, 10116.3214285714, 3477.6,
1562.21774193548, 708.404040404041, 600.507042253521, 3584.57142857143,
1850, 383.333333333333, 564.962962962963, 1510.73684210526, 786.5,
938.4375, 485.378151260504, 1817.6, 183.569060773481, 1492.76033057851,
527.576470588235, 332.897727272727, 565.89387755102, 1773.91836734694,
952.276315789474, 307.272727272727, 1252.25090909091, 1228.39655172414,
1013.6, 4861.95652173913, 1616.68376068376, 2561.63636363636,
1364, 2376, 1834.41935483871, 1268, 1308.07692307692, 644.936305732484,
3787.82608695652, 297.052631578947, 673.941176470588, 3490.77777777778,
714.659685863874, 703.706161137441, 809.851485148515, 354, 900.014492753623,
941.627118644068, 492.623762376238, 1142.01754385965, 215.305970149254,
1389.71856287425, 755.328947368421, 1112.01550387597, 372, 7842.03125,
261.075, 4404.4, 1842.67741935484, 244.776119402985, 1534.25,
1109.07843137255, 970.430379746835, 1994.62295081967, 1127.88,
524.21686746988, 790.533333333333, 2408, 1809.44262295082, 1028.61111111111,
2482.2, 1572.08333333333, 1179.75, 669.636363636364, 135.310344827586,
318.09375, 1757.61538461538, 2004.73684210526, 373.30985915493,
663.650655021834, 1437.64705882353, 1032, 1957.44230769231, 295.454545454545,
1506.18181818182, 705.295774647887, 726.701086956522, 4895.06172839506,
317.914893617021, 1366.73333333333, 755.238095238095, 245.285714285714,
277.524861878453, 1046.07092198582, 3483, 1550.25, 570.175732217573,
1499.30769230769, 472.5, 2346.14925373134, 490.284768211921,
965.083333333333, 388.298850574713, 564.128712871287, 1006.48387096774,
3645.28395061728, 2626.8, 1447.47407407407, 450.355450236967,
2111.53846153846, 324.161073825503, 496.960396039604, 2723.36842105263,
1406, 544.212871287129, 389.924050632911, 554.50643776824, 726.220183486238,
804.132911392405, 478.802197802198, 1033.5, 184.046920821114,
864.440366972477, 984, 141.617647058824, 3814.56666666667, 666.793103448276,
476.096885813149, 815.006849315069, 503.076923076923, 1014.6,
1147.62886597938, 1114.46913580247, 351.368, 4129.81132075472,
1806.53191489362, 971.8125, 552.716814159292, 3391.875, 1165.28888888889,
445.551724137931, 387.775862068966, 568.85549132948, 2608.66666666667,
1332.16901408451, 1288.76712328767, 7250.31818181818, 1155, 2054.8640776699,
540.555555555556, 1529.07291666667, 940.50279329609, 1422.16666666667,
1587.14285714286, 366.47703180212, 2999.11764705882, 1333.45508982036,
2661.36842105263, 117.123287671233, 1859.14285714286, 741.348837209302,
893.714285714286, 1645.21428571429, 789.195945945946, 919.1875,
1036.8, 586.5, 406, 650.325, 1071.5690376569, 396.86320754717
)), row.names = c(NA, -177L), class = c("tbl_df", "tbl", "data.frame"
))
## plot1
ggplot(df, aes(x=Score))
geom_histogram( aes(y=..count..,color=Enroll, fill=Enroll), bins = 177)
geom_density(aes(y = ..count..), alpha=.2, fill="#FF6666")
## plot2
CodePudding user response:
A few options, none of which are perfect: the first two do not achieve "perfect" alignment, and the third is manual.
(FYI: after_stat(count) is now preferred over ..count.., see ?after_stat. Not a breaking thing, just a "btw".)
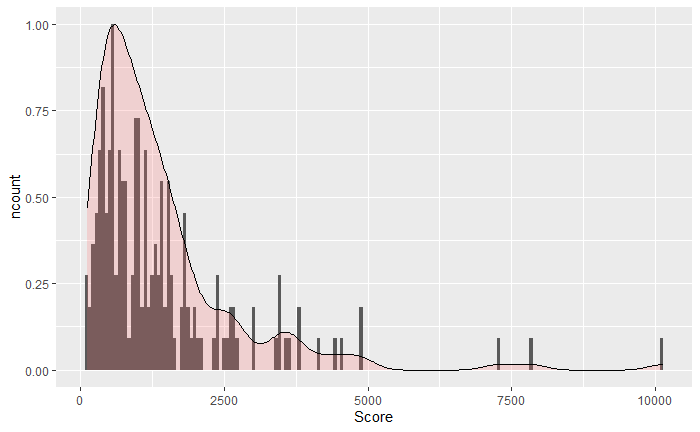
Change the histogram to proportion,
ggplot(df, aes(x=Score)) geom_histogram( aes(y = after_stat(count/sum(count)), color=Enroll, fill=Enroll), bins = 177) geom_density(aes(y = after_stat(count)), alpha=.2, fill="#FF6666")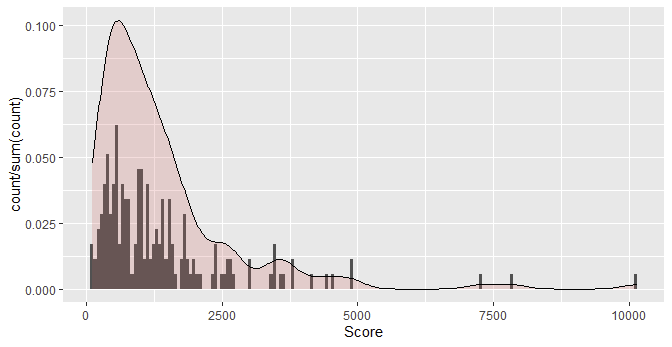
Scale the density dynamically:
ggplot(df, aes(x=Score)) geom_histogram( aes(y = after_stat(count), color=Enroll, fill=Enroll), bins = 177) geom_density(aes(y = after_stat(count / max(count))), alpha=.2, fill="#FF6666")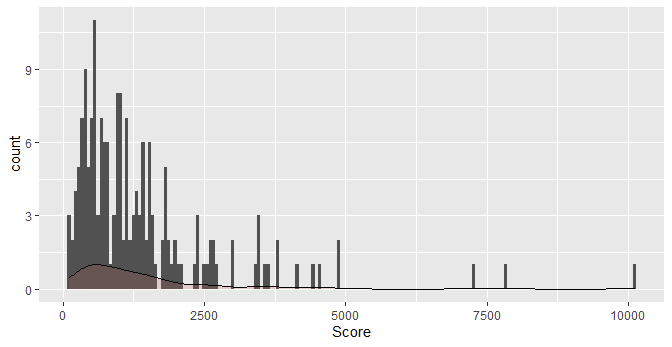
Scale the density arbitrarily (not dynamic), found by manual iteration:
ggplot(df, aes(x=Score)) geom_histogram( aes(y = after_stat(count),color=Enroll, fill=Enroll), bins = 177) geom_density(aes(y = 108 * after_stat(count)), alpha=.2, fill="#FF6666")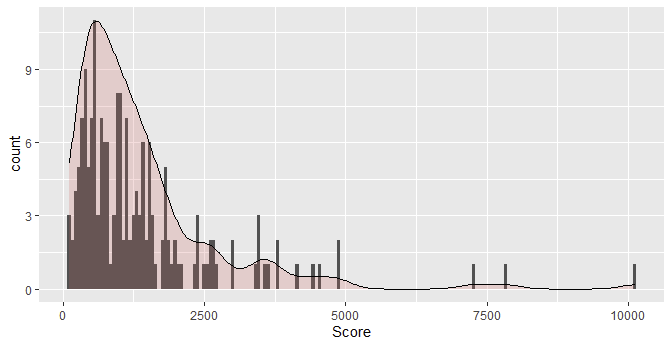
CodePudding user response:
Normally, we can approximate density to fit ..count.. by multiplying ..count.. with binwdith size. However, here you are using bins instead of binwidth, we need to adjust it further.
library(ggplot2)
ggplot(df, aes(x=Score))
geom_histogram( aes(y=..count..,color=Enroll, fill=Enroll), bins = 177)
geom_density(aes(y = ..count.. * 177*2/3), alpha=.2, fill="#FF6666")