Please, I know there are several issues related to this error of mine, but I'm learning, I don't understand almost anything, so please, if it's not asking too much, help me fix this code.
I am totally layman and difficult to learn. Sorry to repeat the same problems, but I need help with this, I've been trying to solve something that should be very simple but for me is complex.
The error:
Traceback (most recent call last):
File "d:\Mir4\RankMir4-TesteRank\RankMir4-TesteRank\RankCla.py", line 73, in <module>
membro['Ranking'] = membro['Ranking'].split(' ')
AttributeError: 'int' object has no attribute 'split'
PS D:\Mir4\RankMir4-TesteRank\RankMir4-TesteRank>
The code:
from __future__ import print_function
from msvcrt import LK_LOCK
import os.path
from google.auth.transport.requests import Request
from google.oauth2.credentials import Credentials
from google_auth_oauthlib.flow import InstalledAppFlow
from googleapiclient.discovery import build
from googleapiclient.errors import HttpError
import numpy as np
import datetime
import json
import time
import pandas as pd
from bs4 import BeautifulSoup
from prompt_toolkit import print_formatted_text
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.firefox.options import Options
data = np.empty_like
data = datetime.datetime.now()
data_atual = data.strftime('%d/%m/%Y')
hora_atual = data.strftime('%H:%M')
data = [f"Atualizado em {data_atual} às {hora_atual}h"]
data_atualizacao = np.array([data]).tolist()
configs = pd.read_json('configs.json').to_dict('records')
for config in configs:
cla = np.array(config['clan'])
mundo = str(config['mundo'])
grupo_mundo = str(config['grupo_mundo'])
planilha_id = str(config['planilha_id'])
range_titulo = str(config['range_titulo'])
range_planilha = str(config['range_planilha'])
atualizado_em = str(config['atualizado_em'])
url = f"https://forum.mir4global.com/rank?ranktype=1&worldgroupid={grupo_mundo}&worldid={mundo}"
multi_cla = np.empty((0, 1), int)
for array_cla in cla:
multi_cla = np.append(multi_cla, np.array([[array_cla]]), axis=0).tolist()
option = Options()
option.headless = True
driver = webdriver.Firefox()
driver.get(url)
time.sleep(5)
for i in range(9):
driver.find_element(by=By.CLASS_NAME, value='btn_flat').click()
time.sleep(2)
html_conteudo = driver.find_elements(
by=By.CLASS_NAME,
value="rank_section"
)[2].get_attribute("innerHTML")
soup = BeautifulSoup(html_conteudo, 'html.parser')
tabela = soup.find(name='table')
tabela_completa = pd.read_html(str(tabela))[0]
info_tabela = {}
info_tabela = tabela_completa.to_dict('records')
teste = []
membro_clan = []
clan_ = []
linha_array = np.empty((0, 5), int)
rank_cla = 1
for membro in info_tabela:
for cla_ in cla:
if membro['Clan'] == cla_:
membro['Ranking'] = membro['Ranking'].split(' ')
membro['Ranking'] = membro['Ranking'][0]
teste.append(membro)
linha_array = np.append(linha_array,
np.array([
[
rank_cla,
membro['Ranking'],
membro['Character'],
membro['Clan'],
membro['Power Score']
]]), axis=0
).tolist()
rank_cla = rank_cla 1
js = json.dumps(linha_array)
fp = open('membros.json', 'w')
fp.write(js)
fp.close
driver.quit
'''
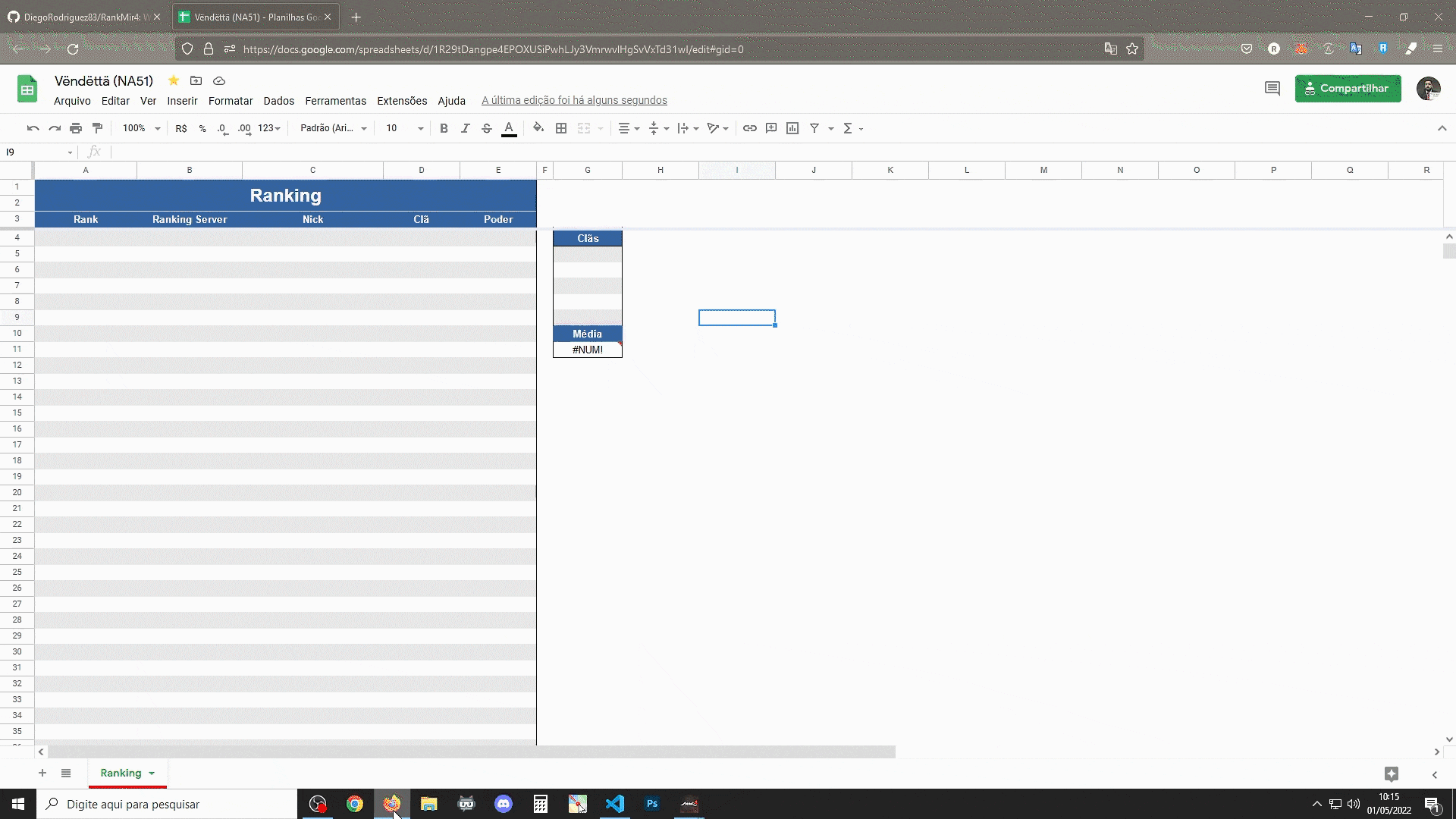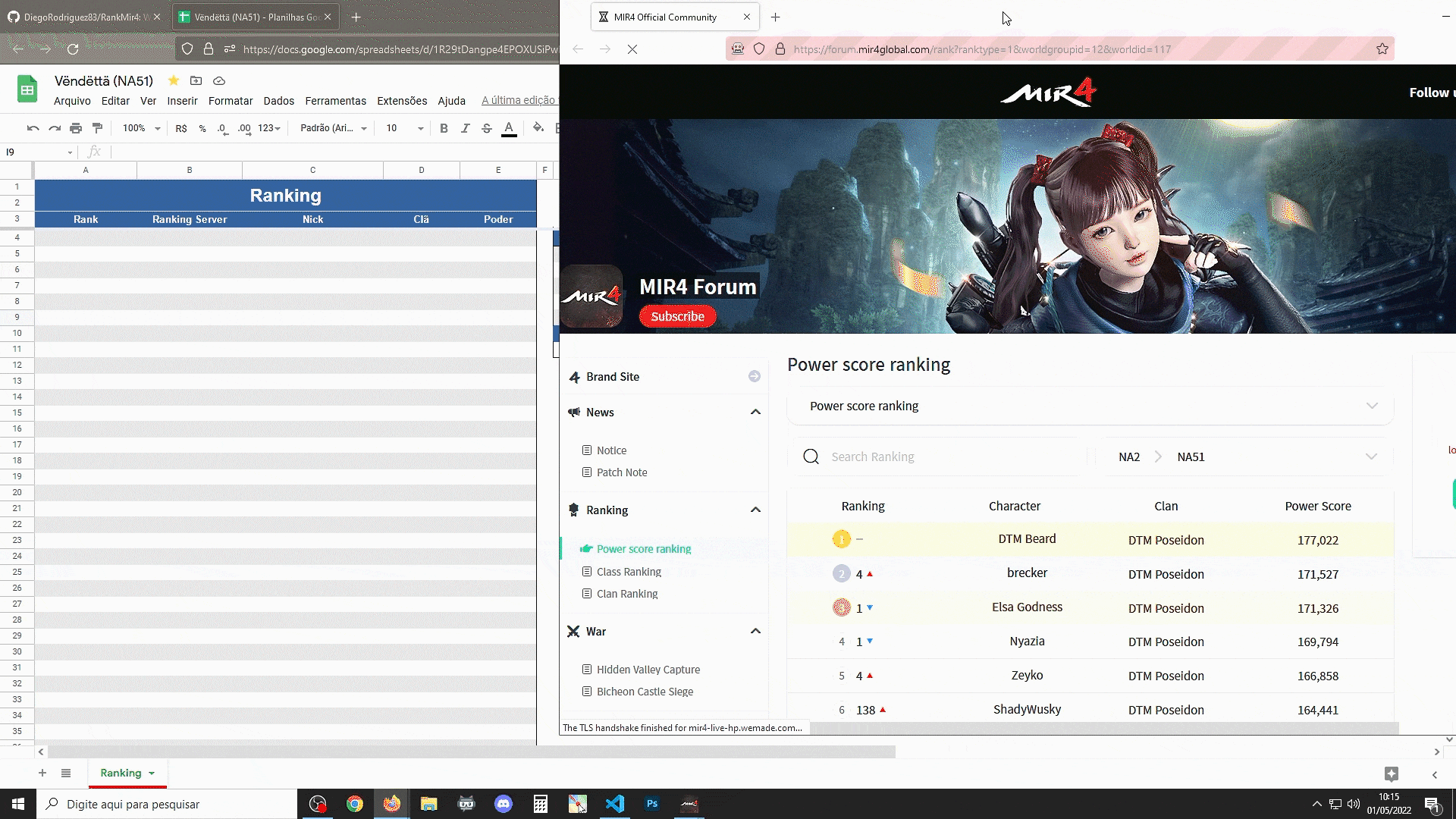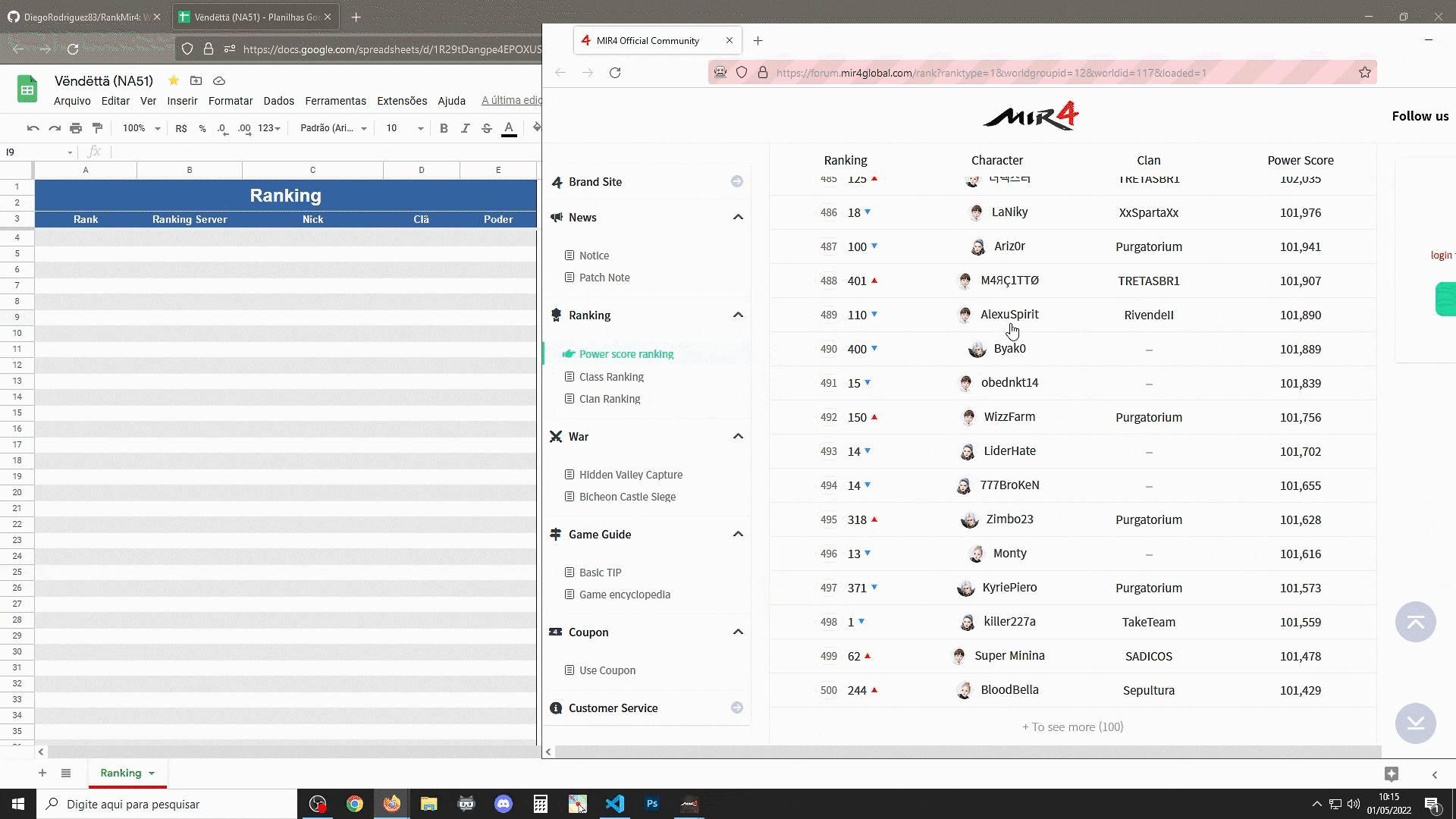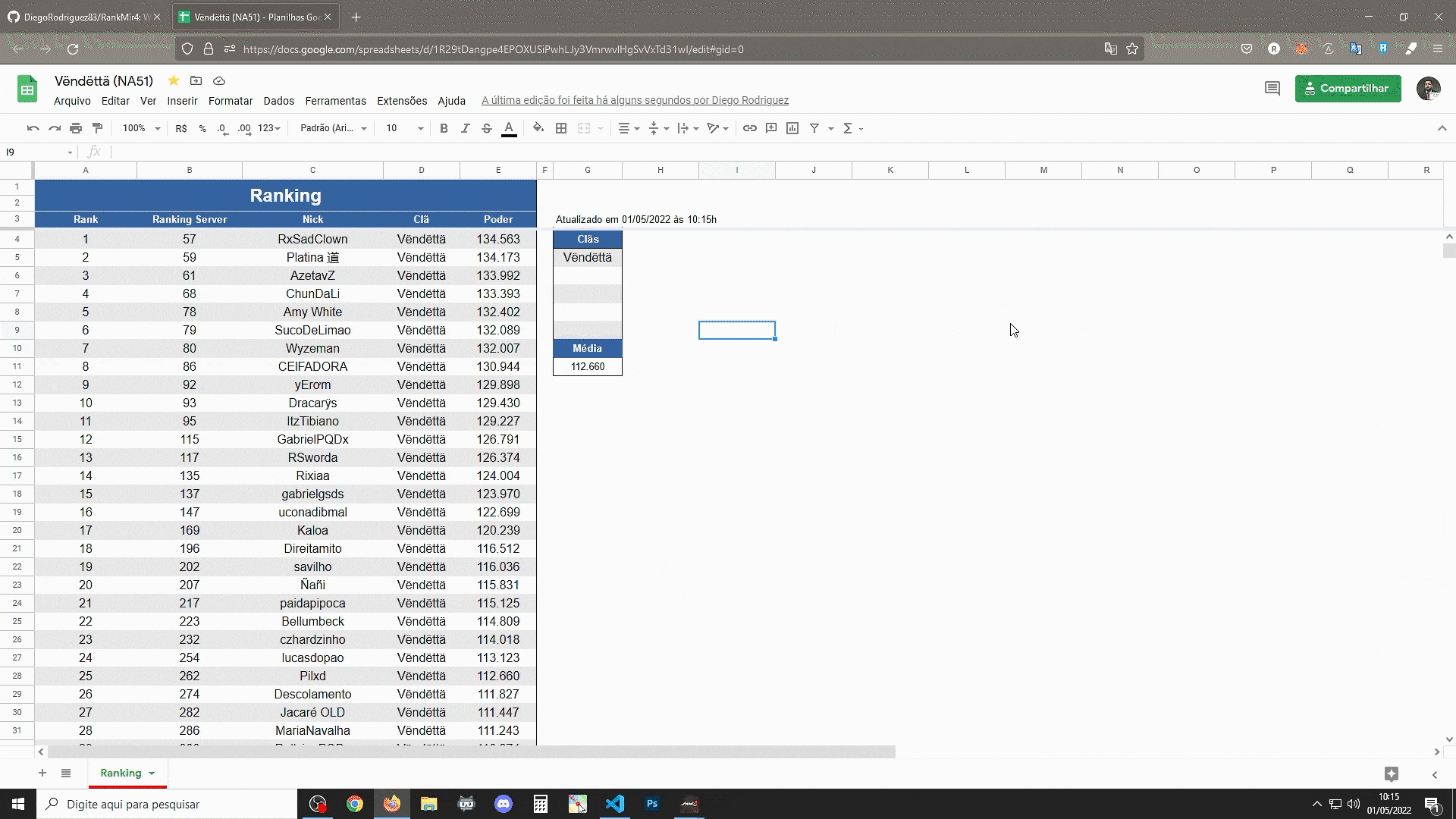
When running the script, it opens a FireFox (selenium) tab and starts checking the leaderboard which is formatted as in the image:
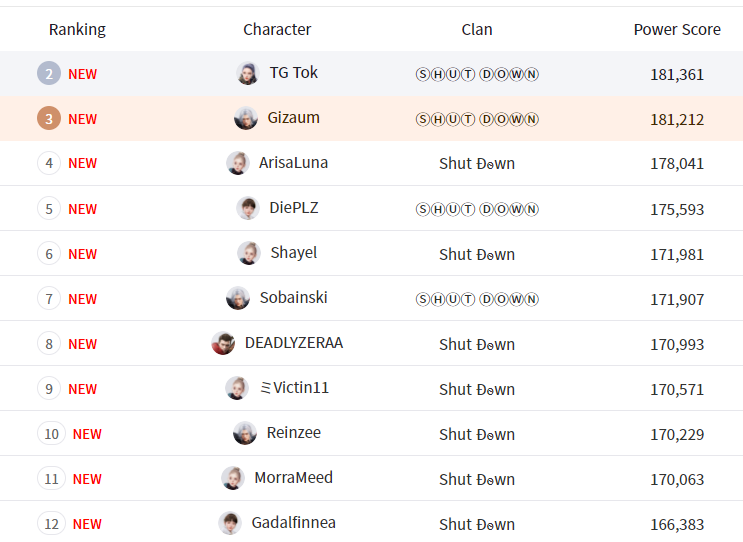
Collecting in the html the Ranking, Character, Clan and Power Score.
If everything goes well, the result is to be saved in "membros.json" ex:
[["1", "57", "RxSadClown", "V\u00ebnd\u00ebtt\u00e4", "134563"], ["2", "59", "Platina \u9053", "V\u00ebnd\u00ebtt\u00e4", "134173"], ["3", "61", "AzetavZ", "V\u00ebnd\u00ebtt\u00e4", "133992"], ["4", "68", "ChunDaLi", "V\u00ebnd\u00ebtt\u00e4", "133393"], ["5", "78", "Amy White", "V\u00ebnd\u00ebtt\u00e4", "132402"], ["6", "79", "SucoDeLimao", "V\u00ebnd\u00ebtt\u00e4", "132089"], ["7", "80", "Wyzeman", "V\u00ebnd\u00ebtt\u00e4", "132007"], ["8", "86", "CElFADORA", "V\u00ebnd\u00ebtt\u00e4", "130944"], ["9", "92", "yEr\u01a1m", "V\u00ebnd\u00ebtt\u00e4", "129898"], ["10", "93", "Dracar\u00ffs", "V\u00ebnd\u00ebtt\u00e4", "129430"], ["11", "95", "ItzTibiano", "V\u00ebnd\u00ebtt\u00e4", "129227"], ["12", "115", "GabrielPQDx", "V\u00ebnd\u00ebtt\u00e4", "126791"], ["13", "117", "RSworda", "V\u00ebnd\u00ebtt\u00e4", "126374"], ["14", "135", "Rixiaa", "V\u00ebnd\u00ebtt\u00e4", "124004"], ["15", "137", "gabrielgsds", "V\u00ebnd\u00ebtt\u00e4", "123970"], ["16", "147", "uconadibmal", "V\u00ebnd\u00ebtt\u00e4", "122699"], ["17", "169", "Kaloa", "V\u00ebnd\u00ebtt\u00e4", "120239"], ["18", "196", "Direitamito", "V\u00ebnd\u00ebtt\u00e4", "116512"], ["19", "202", "savilho", "V\u00ebnd\u00ebtt\u00e4", "116036"], ["20", "207", "\u00d1a\u00f1i", "V\u00ebnd\u00ebtt\u00e4", "115831"], ["21", "217", "paidapipoca", "V\u00ebnd\u00ebtt\u00e4", "115125"], ["22", "223", "Bellumbeck", "V\u00ebnd\u00ebtt\u00e4", "114809"], ["23", "232", "czhardzinho", "V\u00ebnd\u00ebtt\u00e4", "114018"], ["24", "254", "lucasdopao", "V\u00ebnd\u00ebtt\u00e4", "113123"], ["25", "262", "Pilxd", "V\u00ebnd\u00ebtt\u00e4", "112660"], ["26", "274", "Descolamento", "V\u00ebnd\u00ebtt\u00e4", "111827"], ["27", "282", "Jacar\u00e9 OLD", "V\u00ebnd\u00ebtt\u00e4", "111447"], ["28", "286", "MariaNavalha", "V\u00ebnd\u00ebtt\u00e4", "111243"], ["29", "300", "RellxionPQDx", "V\u00ebnd\u00ebtt\u00e4", "110274"], ["30", "309", "topdog11", "V\u00ebnd\u00ebtt\u00e4", "109811"], ["31", "310", "Carcass77", "V\u00ebnd\u00ebtt\u00e4", "109794"], ["32", "315", "Kakaroto7", "V\u00ebnd\u00ebtt\u00e4", "109512"], ["33", "330", "YellowIsa", "V\u00ebnd\u00ebtt\u00e4", "108387"], ["34", "337", "BMGaming14", "V\u00ebnd\u00ebtt\u00e4", "107893"], ["35", "342", "LeozinDx", "V\u00ebnd\u00ebtt\u00e4", "107685"], ["36", "361", "shipudenpqd", "V\u00ebnd\u00ebtt\u00e4", "106960"], ["37", "374", "Drawsinger", "V\u00ebnd\u00ebtt\u00e4", "106458"], ["38", "379", "KpetinhaS2", "V\u00ebnd\u00ebtt\u00e4", "106249"], ["39", "381", "Venush", "V\u00ebnd\u00ebtt\u00e4", "106075"], ["40", "392", "Bob Lanceiro", "V\u00ebnd\u00ebtt\u00e4", "105577"], ["41", "403", "Oscar R", "V\u00ebnd\u00ebtt\u00e4", "105284"], ["42", "416", "Pame", "V\u00ebnd\u00ebtt\u00e4", "104863"], ["43", "423", "Marph", "V\u00ebnd\u00ebtt\u00e4", "104662"], ["44", "428", "Lady\u00a0Loira", "V\u00ebnd\u00ebtt\u00e4", "104511"], ["45", "452", "Sirohh", "V\u00ebnd\u00ebtt\u00e4", "103382"], ["46", "479", "isabelebr", "V\u00ebnd\u00ebtt\u00e4", "102301"], ["47", "531", "lSABELLY", "V\u00ebnd\u00ebtt\u00e4", "100301"], ["48", "580", "GRETTINHA", "V\u00ebnd\u00ebtt\u00e4", "98260"], ["49", "583", "Thundoxa", "V\u00ebnd\u00ebtt\u00e4", "98180"]]
After being collected and treated, the data will be inserted into a google sheets via api using a credential with this code below:
def main():
SCOPES = ['https://www.googleapis.com/auth/spreadsheets']
creds = None
if os.path.exists('token.json'):
creds = Credentials.from_authorized_user_file('token.json', SCOPES)
if not creds or not creds.valid:
if creds and creds.expired and creds.refresh_token:
creds.refresh(Request())
else:
flow = InstalledAppFlow.from_client_secrets_file(
'client_secret.json', SCOPES)
creds = flow.run_local_server(port=0)
with open('token.json', 'w') as token:
token.write(creds.to_json())
try:
service = build('sheets', 'v4', credentials=creds)
sheet = service.spreadsheets()
sheet.values().clear(
spreadsheetId=planilha_id,
range='Ranking!A4:E150',
body={}
).execute()
sheet.values().clear(
spreadsheetId=planilha_id,
range='Ranking!G5:G9',
body={}
).execute()
sheet.values().update(
spreadsheetId=planilha_id,
range=range_titulo,
valueInputOption="USER_ENTERED",
body={"values": multi_cla}
).execute()
sheet.values().update(
spreadsheetId=planilha_id,
range='Ranking!A4',
valueInputOption="USER_ENTERED",
body={"values": linha_array}
).execute()
sheet.values().update(
spreadsheetId=planilha_id,
range=atualizado_em,
valueInputOption="USER_ENTERED",
body={"values": data_atualizacao}
).execute()
except HttpError as err:
print(err)
if __name__ == '__main__':
main()
The problem is that it's not getting past that first error, I don't know if there are more.
CodePudding user response:
The problem is caused by pandas in the line tabela_completa = pd.read_html(str(tabela))[0] automatically converting from string to integer. This is why the error message is telling you that it can't use .split on an integer.
Since there are additional issues described in the comments, it may be best to post a new question that is specific to just the code causing the new issues.