Is there an alternative way to append a dataframe to itself N times where N is based on a list length, and the list contents are added as a new column to the dataframe?
For example, with this dataframe and list:
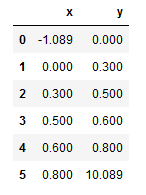
df = pd.DataFrame(
{
"x": [-1.089, 0, 0.3, 0.5, 0.6, 0.8],
"y": [0, 0.3, 0.5, 0.6, 0.8, 10.089],
}
)
z = [11, 12, 13, 14, 15, 16]
display(df)
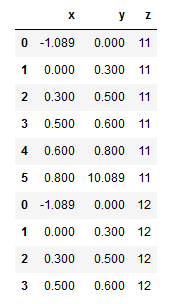
This example does what I want, but I think it might be inefficient or nonpythonic.
df2 = pd.DataFrame()
for i in z:
temp = df.copy()
temp['z'] = i
df2 = df2.append(temp)
display(df2.head(10))
CodePudding user response:
here is one way:
out = df.merge(pd.Series(z,name='z'), how='cross')
output:
>> out.head(10)
x y z
0 -1.089 0.0 11
1 -1.089 0.0 12
2 -1.089 0.0 13
3 -1.089 0.0 14
4 -1.089 0.0 15
5 -1.089 0.0 16
6 0.000 0.3 11
7 0.000 0.3 12
8 0.000 0.3 13
9 0.000 0.3 14
in pandas before < 1.2 :
df_z = pd.Dataframe(z, columns='z')
df_z['key'] = 0
df['key'] = 0
out = df.merge(df_z,on='key').drop("key", 1)
CodePudding user response:
You can try assgin the list to a new column then explode that column and at last sort the value
df = (df.assign(z=[z for _ in range(len(df))])
.explode('z')
.sort_values('z', kind='stable', ignore_index=True))
print(df.head(10))
x y z
0 -1.089 0.000 11
1 0.000 0.300 11
2 0.300 0.500 11
3 0.500 0.600 11
4 0.600 0.800 11
5 0.800 10.089 11
6 -1.089 0.000 12
7 0.000 0.300 12
8 0.300 0.500 12
9 0.500 0.600 12