I have a table from which I want to select values, but only if there is exactly one entry in the column "id_new". After I have selected those ids, I would update these ids and mark them as "ready" in the source table. Those ids (id_orig) would be ignored if the select would run again. The problem is, that there could be many steps needed to find all entries, which have exactly one entry for "id_new".
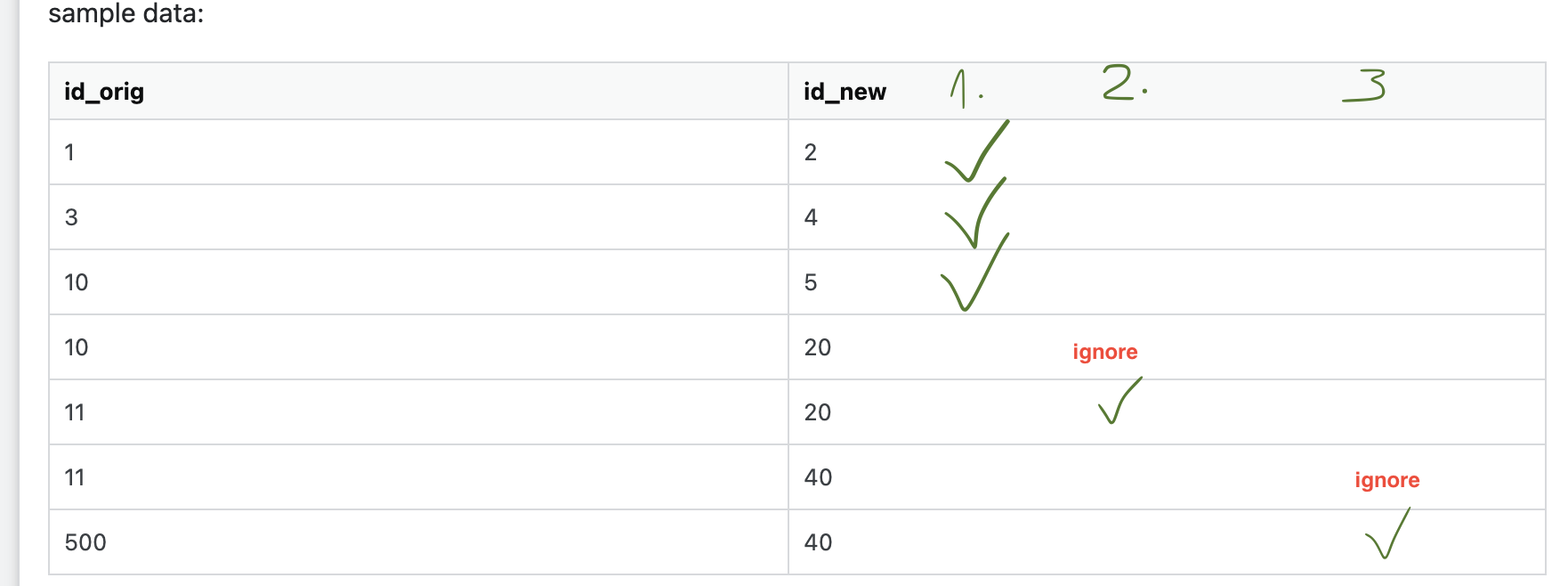
sample data:
| id_orig | id_new |
|---|---|
| 1 | 2 |
| 3 | 4 |
| 10 | 5 |
| 10 | 20 |
| 11 | 20 |
| 11 | 40 |
| 500 | 40 |
For the sample data it would mean:
1.) select all columns where there is only one entry for id_new.
2.) redo the same sql but ignore the columns where id_orig was already selected. This would result in finding (11, 20). I could repeat this and would find (500, 40) in the third step.
 I also wrote a long sql to find the same rows, but I am wondering if you can achieve the same result in a simpler way, maybe recursive?
I also wrote a long sql to find the same rows, but I am wondering if you can achieve the same result in a simpler way, maybe recursive?
select * from mytable where id_new in (select id_new from mytable group by id_new having count(*) = 1)
union
select a.* from mytable a
where a.id_new in (select id_new from mytable where id_orig in
(select id_orig from mytable where id_new in
(select id_new from mytable group by id_new having count(*) = 1)))
and a.id_orig not in (
select id_orig from mytable where id_new in (select id_new from mytable group by id_new having count(*) = 1))
union all
select a.* from mytable a
where a.id_new in ( select id_new from mytable where id_orig in (select id_orig from mytable where id_new in (
select a.id_new from mytable a
where a.id_new in (select id_new from mytable where id_orig in
(select id_orig from mytable where id_new in
(select id_new from mytable group by id_new having count(*) = 1)))
and a.id_orig not in (
select id_orig from mytable where id_new in (select id_new from mytable group by id_new having count(*) = 1))
)))
and a.id_orig not in (
select id_orig from mytable where id_new in (select id_new from mytable group by id_new having count(*) = 1)
union all
select a.id_orig from mytable a
where a.id_new in (select id_new from mytable where id_orig in
(select id_orig from mytable where id_new in
(select id_new from mytable group by id_new having count(*) = 1)))
and a.id_orig not in (
select id_orig from mytable where id_new in (select id_new from mytable group by id_new having count(*) = 1))
)
CodePudding user response:
Maybe a window function would help eg ROW_NUMBER() (see documentation).
select id_orig, id_new
, row_number() over ( partition by id_orig order by id_new ) rn_
from t ;
-- result
id_orig id_new rn_
1 2 1
3 4 1
10 5 1
10 20 2 -- 2 rows for this id!
11 20 1
11 40 2 -- 2 rows for this id!
500 40 1
Once you have this result, you can eliminate all the extraneous rows by using the initial query as a subquery, and adding a WHERE clause:
select *
from (
select id_orig, id_new
, row_number() over ( partition by id_orig order by id_new ) rn_
from t
) sq
where rn_ = 1 ;
--result
id_orig id_new rn_
1 2 1
3 4 1
10 5 1
11 20 1
500 40 1
(If you don't want the rn_ column in the output, just write SELECT id_orig, id_ new ... in the outer query.)
CodePudding user response:
You can UNION, all single number with all Dup0licates, that have the higher id_orig.
select MIN(t.id_orig) as id_orig, t.id_new from t GROUP BY t.id_new HAVING COUNT(*) = 1 UNION select t.id_orig, t.id_new from t INNER JOIN t as t1 ON t.id_new = t1.id_new AND t.id_orig > t1.id_orig;id_orig | id_new ------: | -----: 1 | 2 3 | 4 10 | 5 11 | 20 500 | 40
db<>fiddle here