I'd really use some help with scraping the data from the line or donut charts on the website 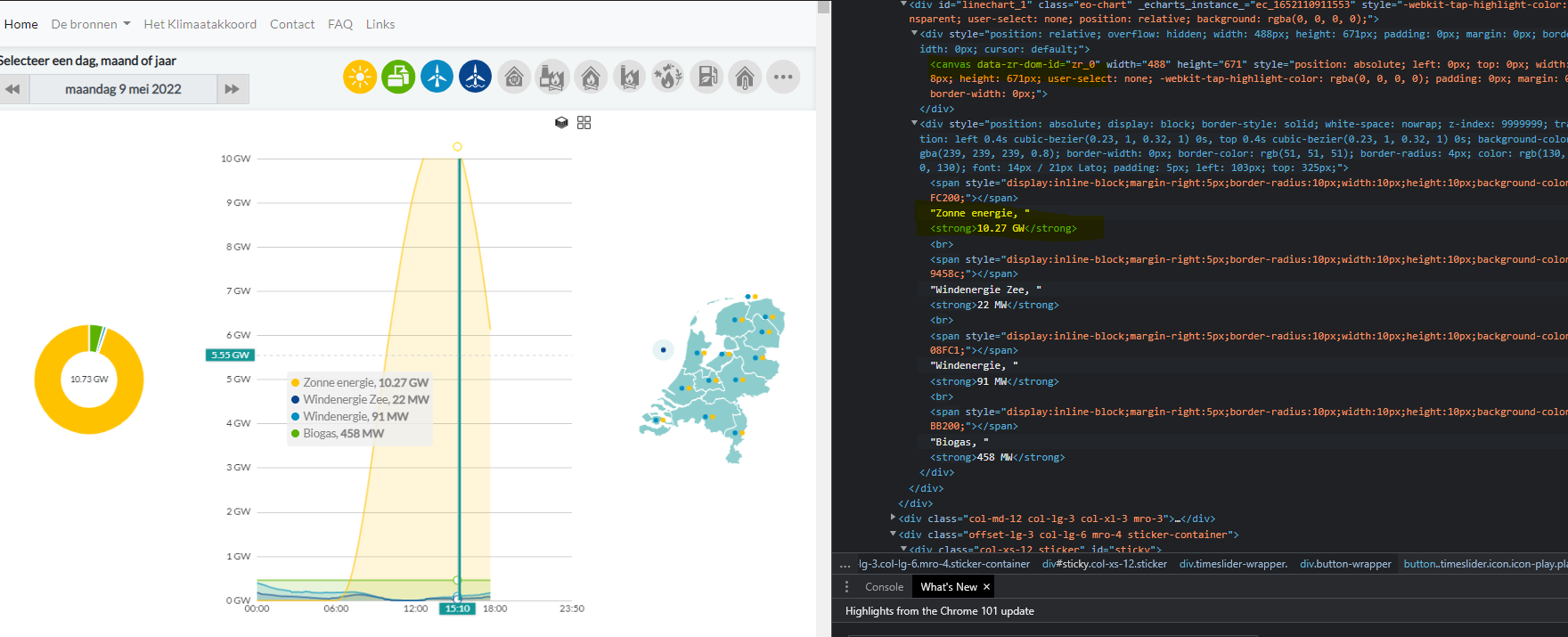
The problem is, however, that I'm not able to receive the data in the page source. Probably because I'm not not able to figure out how to hover the mouse over the chart using Selenium.
My initial code is:
chrome_driver_path = pathlib.Path(__file__).parent / "chromedriver"
options = webdriver.ChromeOptions()
options.add_argument('headless')
driver = webdriver.Chrome(executable_path=chrome_driver_path,options=options)
url = "https://energieopwek.nl"
driver.get(url)
line_chart=driver.find_element(By.ID,"linechart_1")
action.move_to_element(line_chart).click().perform() # clicking on the chart
soup = BeautifulSoup(driver.page_source, 'lxml')
print(soup.prettify()) # I'd expect to see the data in the page source, but it's not
Here is the page source output. I'd have expected data from the chart to be present in the divs, as in the screen-shot above:
<div _echarts_instance_="ec_1652165210746" id="linechart_1" style="-webkit-tap-highlight-color: transparent; user-select: none; position: relative; background: rgba(0, 0, 0, 0);">
<div style="position: relative; overflow: hidden; width: 744px; height: 385px; padding: 0px; margin: 0px; border-width: 0px; cursor: default;">
<canvas data-zr-dom-id="zr_0" height="385" style="position: absolute; left: 0px; top: 0px; width: 744px; height: 385px; user-select: none; -webkit-tap-highlight-color: rgba(0, 0, 0, 0); padding: 0px; margin: 0px; border-width: 0px;" width="744">
</canvas>
</div>
<div>
--- WHERE IS THE DATA?---
</div>
</div>Curious to hear if anybody is able to help me here ?
CodePudding user response:
You can take a screenshot with selenium then crop it automatically. Here's an example of something like that I've done before.
element = driver.find_element_by_xpath('//*[@id="THIS_WEEK"]')
location = element.location
size = element.size
driver.save_screenshot("due.png")
x = location['x']
y = location['y']
w = size['width']
h = size['height']
width = x w
height = y h
im = Image.open('due.png')
im = im.crop((int(x), int(y), int(width), int(height)))
im.save('due.png')
CodePudding user response:
If this is for a project you are going to publish you should reach to the source asking for permission, or get lawyers involved to make sure you are not breaking the Terms of service on that site. I get a feeling they might have obfuscated the data to prevent what you are trying to do.
About my comment and the data available on:
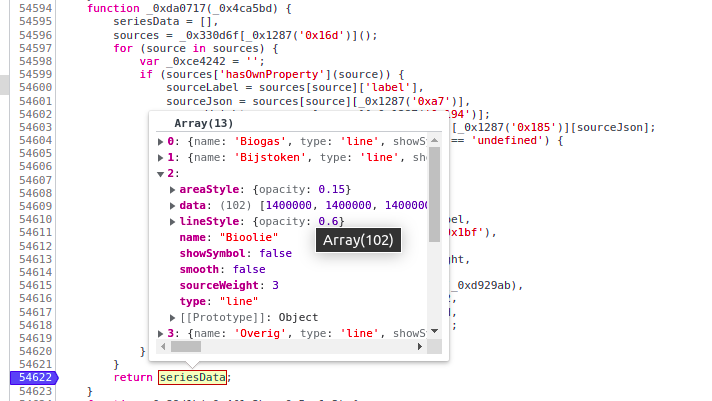
If you know how to use debug on the developer console that is your start point
And it looks like there is a way to read JS variables from selenium if that is what you prefer using:
Reading JavaScript variables using Selenium WebDriver