I am trying to figure out how to plot the decision boundary line picking just few middle values instead of the entirety of the separator line such that it spans roughly the y-range that also the observations span.
Currently, I manually repeatedly select different bounds and assess visually, until "a good looking separator" emerged.
MWE:
from collections import Counter
from sklearn.datasets import make_classification
import matplotlib.pyplot as plt
import numpy as np
from sklearn.svm import SVC
# sample data
X, y = make_classification(n_samples=100, n_features=2, n_redundant=0,
n_clusters_per_class=1, weights=[0.9], flip_y=0, random_state=1)
# fit svm model
svc_model = SVC(kernel='linear', random_state=32)
svc_model.fit(X, y)
# Constructing a hyperplane using a formula.
w = svc_model.coef_[0]
b = svc_model.intercept_[0]
x_points = np.linspace(-1, 1)
y_points = -(w[0] / w[1]) * x_points - b / w[1]
Figure 1:
decision boundary line spans of a much larger range, causing the observations to be "squished" on what visually looks like almost a line
plt.figure(figsize=(10, 8))
# Plotting our two-features-space
sns.scatterplot(x=X[:, 0], y=X[:, 1], hue=y, s=50)
# Plotting a red hyperplane
plt.plot(x_points, y_points, c='r')
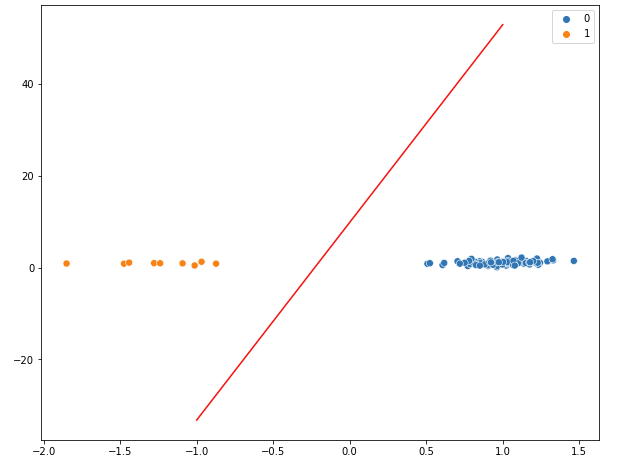
Figure 2
Manually play around with points to determine good fit visually (x_points[19:-29], y_points[19:-29] ):
plt.figure(figsize=(10, 8))
# Plotting our two-features-space
sns.scatterplot(x=X[:, 0], y=X[:, 1], hue=y, s=50)
# Plotting a red hyperplane
plt.plot(x_points[19:-29], y_points[19:-29], c='r')
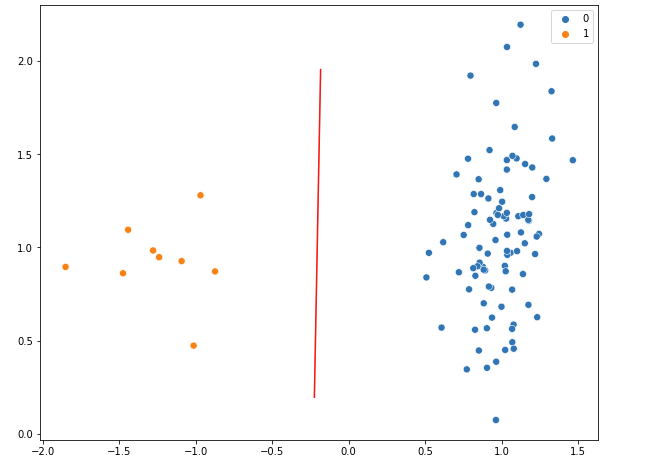
How can I automate "good fit" range of values? Foe example, this works fine with n_samples=100 data points but not with n_samples=1000.
CodePudding user response:
Instead of having x_points go from -1 to 1, you could invert the linear equation and specify the bounds you want on y_points directly:
y_points = np.linspace(X[:, 1].min(), X[:, 1].max())
x_points = -(w[1] * y_points b) / w[0]