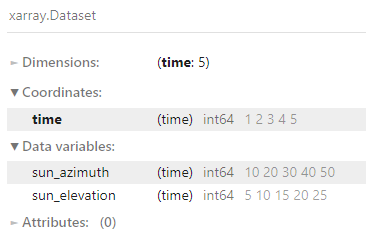
I have an xarray.Dataset with two 1D variables sun_azimuth and sun_elevation with multiple timesteps along the time dimension:
import xarray as xr
import numpy as np
ds = xr.Dataset(
data_vars={
"sun_azimuth": ("time", [10, 20, 30, 40, 50]),
"sun_elevation": ("time", [5, 10, 15, 20, 25]),
},
coords={"time": [1, 2, 3, 4, 5]},
)
ds
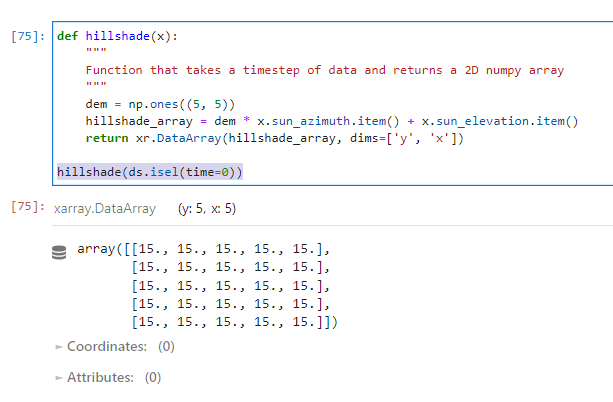
I also have a function similar to this that I want to apply to each timestep that uses the sun_azimuth and sun_elevation to output a 2D array:
def hillshade(x):
"""
Function that takes a timestep of data, and uses
sun_azimuth and sun_elevation values to output a 2D array
"""
dem = np.ones((5, 5))
hillshade_array = dem * x.sun_azimuth.item() x.sun_elevation.item()
return xr.DataArray(hillshade_array, dims=['y', 'x'])
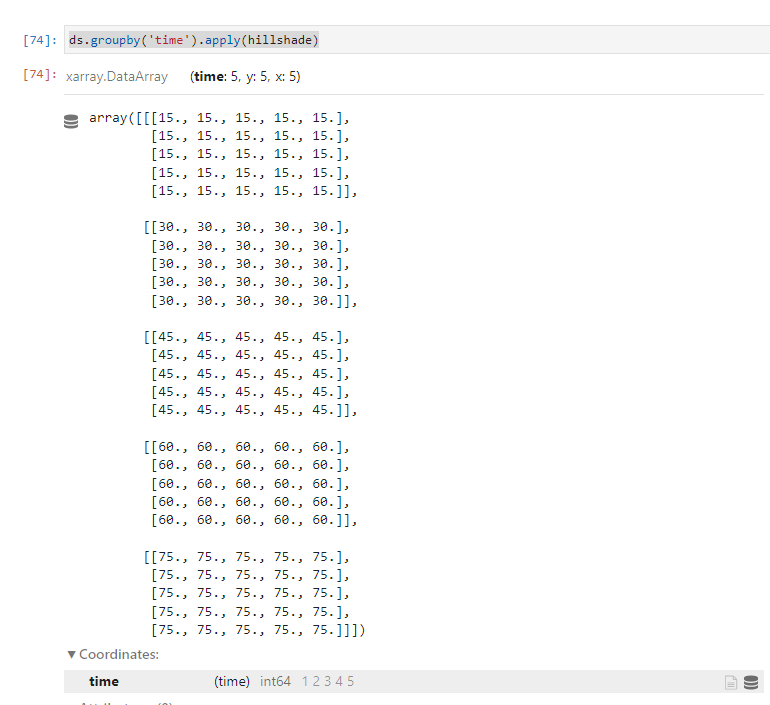
I know I can apply this func to each timestep like this:
ds.groupby('time').apply(hillshade)
However, the outputs of this function are large and take up a lot of memory. I really want to be able to do this lazily using Dask, so that I can delay the computation of the function until a later stage to reduce peak memory use.
How can I make my hillshade function return lazy Dask-aware xarray arrays instead?
CodePudding user response:
Not sure this solves it completely, but here's one potential lead.
The xarray.Dataset you defined resides in memory, to convert it to a dask representation, we can specify how the dataset should be chunked, e.g. ds.chunk(chunks={"time": 1}) should chunk the data along time dimension.
Now if you look at the printout of the chunked dataset, you will see that instead of actual values, there is information on the underlying dask arrays. Since the dask arrays do not have .item method, the function will need to be refactored to use .data (which yields the underlying dask array):
import numpy as np
import xarray as xr
def mod_hillshade(x):
"""
Function that takes a timestep of data, and uses
sun_azimuth and sun_elevation values to output a 2D array
"""
dem = np.ones((5, 5))
hillshade_array = dem * x.sun_azimuth.data x.sun_elevation.data
return xr.DataArray(hillshade_array, dims=["y", "x"])
ds = xr.Dataset(
data_vars={
"sun_azimuth": ("time", [10, 20, 30, 40, 50]),
"sun_elevation": ("time", [5, 10, 15, 20, 25]),
},
coords={"time": [1, 2, 3, 4, 5]},
)
original_result = ds.groupby("time").apply(mod_hillshade)
lazy_result = ds.chunk(chunks={"time": 1}).groupby("time").apply(mod_hillshade)
print(original_result.equals(lazy_result)) # True
The reason why I am not sure this solves it completely, is that it appears that the function mod_hillshade is evaluated at the time of .apply (this might be fine, but best to check on the actual use case).
To handle case where the evaluation of the function itself is computationally intensive, one solution is to wrap the function in delayed and explicitly apply it on one block at a time:
from dask import compute, delayed
compute(
[delayed(mod_hillshade)(x) for _, x in ds.chunk(chunks={"time": 1}).groupby("time")]
)
CodePudding user response:
Another option would be to use xarray's Dataset.map_blocks(func, args=(), kwargs=None, template=None). It works on a chunked dataset, calling the func argument on a Dataset which is created for each chunk.
Because you're reshaping the array, you need to provide a template, which should have the same shape and chunking pattern as the result.
To set this up, I rewrote your hillshade function to return the extra dimensions of x so it can be mapped over the chunks:
In [2]: def hillshade(x):
...: """
...: Function that takes a timestep of data, and uses
...: sun_azimuth and sun_elevation values to output a 2D array
...: """
...: dem = xr.DataArray(np.ones((5, 5)), dims=['y', 'x'])
...: hillshade_array = dem * x.sun_azimuth x.sun_elevation
...: return hillshade_array
...:
The template array can be created by repeating a chunked empty array. This doesn't cost much in terms of memory but it does require knowing your output shape:
In [3]: template = (xr.DataArray(np.empty(shape=(5, 5), dtype='int64'), dims=['y', 'x']).chunk() * ds.time).chunk({'time': 1})
In [4]: template
Out[4]:
<xarray.DataArray (y: 5, x: 5, time: 5)>
dask.array<rechunk-merge, shape=(5, 5, 5), dtype=int64, chunksize=(5, 5, 1), chunktype=numpy.ndarray>
Coordinates:
* time (time) int64 1 2 3 4 5
Dimensions without coordinates: y, x
At this point, hillshade can be called on each chunk:
In [5]: result = ds.chunk({'time': 1}).map_blocks(hillshade, template=template)
In [6]: result
Out[6]:
<xarray.DataArray (y: 5, x: 5, time: 5)>
dask.array<<this-array>-hillshade, shape=(5, 5, 5), dtype=int64, chunksize=(5, 5, 1), chunktype=numpy.ndarray>
Coordinates:
* time (time) int64 1 2 3 4 5
Dimensions without coordinates: y, x