after applying levenshtein distance algorithm I get a dataframe like this:
| Elemento_lista | Item_ID | Score | idx | ITEM_ID_Coincidencia |
|---|---|---|---|---|
| 4 | 691776 | 100 | 5 | 691777 |
| 4 | 691776 | 100 | 6 | 691789 |
| 4 | 691776 | 100 | 7 | 691791 |
| 5 | 691777 | 100 | 4 | 691776 |
| 5 | 691777 | 100 | 6 | 691789 |
| 5 | 691777 | 100 | 7 | 691791 |
| 6 | 691789 | 100 | 4 | 691776 |
| 6 | 691789 | 100 | 5 | 691777 |
| 6 | 691789 | 100 | 7 | 691791 |
| 7 | 691791 | 100 | 4 | 691776 |
| 7 | 691791 | 100 | 5 | 691777 |
| 7 | 691791 | 100 | 6 | 691789 |
| 9 | 1407402 | 100 | 10 | 1407424 |
| 10 | 1407424 | 100 | 9 | 1407402 |
Elemento_lista column is the index of the element that is compared to others, Item_ID is the id of the element, Score is Score generated by the algorithm, idx is the index of the element that was found as similar (same as Elemento_lista , but for elements that were found as similar), ITEM_ID_Coincidencia is the id of the element found as similar
It´s a small sample of the real DF (More than 300000 rows), I´ll need to drop lines that are the same , for example...if Elemento_lista 4, is equal to idx 5,6,and 7...they are all the same, so I don't need lines where 5 is equal to 4, 6 and 7/ 6 is equal to 4,5,7 and 7 is equal to 4,5,6. The same for each Elemento_Lista : value=9 is equal to idx 10, so...I don't need the line Elemento_Lista 10 is equal to idx 9...How could I drop these lines in order to reduce DF len ???
Final DF should be:
| Elemento_lista | Item_ID | Score | idx | ITEM_ID_Coincidencia |
|---|---|---|---|---|
| 4 | 691776 | 100 | 5 | 691777 |
| 4 | 691776 | 100 | 6 | 691789 |
| 4 | 691776 | 100 | 7 | 691791 |
| 9 | 1407402 | 100 | 10 | 1407424 |
I don´t know how to do this...is it possible?
Thanks in advance
CodePudding user response:
Preparing data like example:
a = [
[4,691776,100,5,691777],
[4,691776,100,6,691789],
[4,691776,100,7,691791],
[5,691777,100,4,691776],
[5,691777,100,6,691789],
[5,691777,100,7,691791],
[6,691789,100,4,691776],
[6,691789,100,5,691777],
[6,691789,100,7,691791],
[7,691791,100,4,691776],
[7,691791,100,5,691777],
[7,691791,100,6,691789],
[9,1407402,100,10,1407424],
[10,1407424,100,9,1407402]
]
c = ['Elemento_lista', 'Item_ID', 'Score', 'idx', 'ITEM_ID_Coincidencia']
df = pd.DataFrame(data = a, columns = c)
df
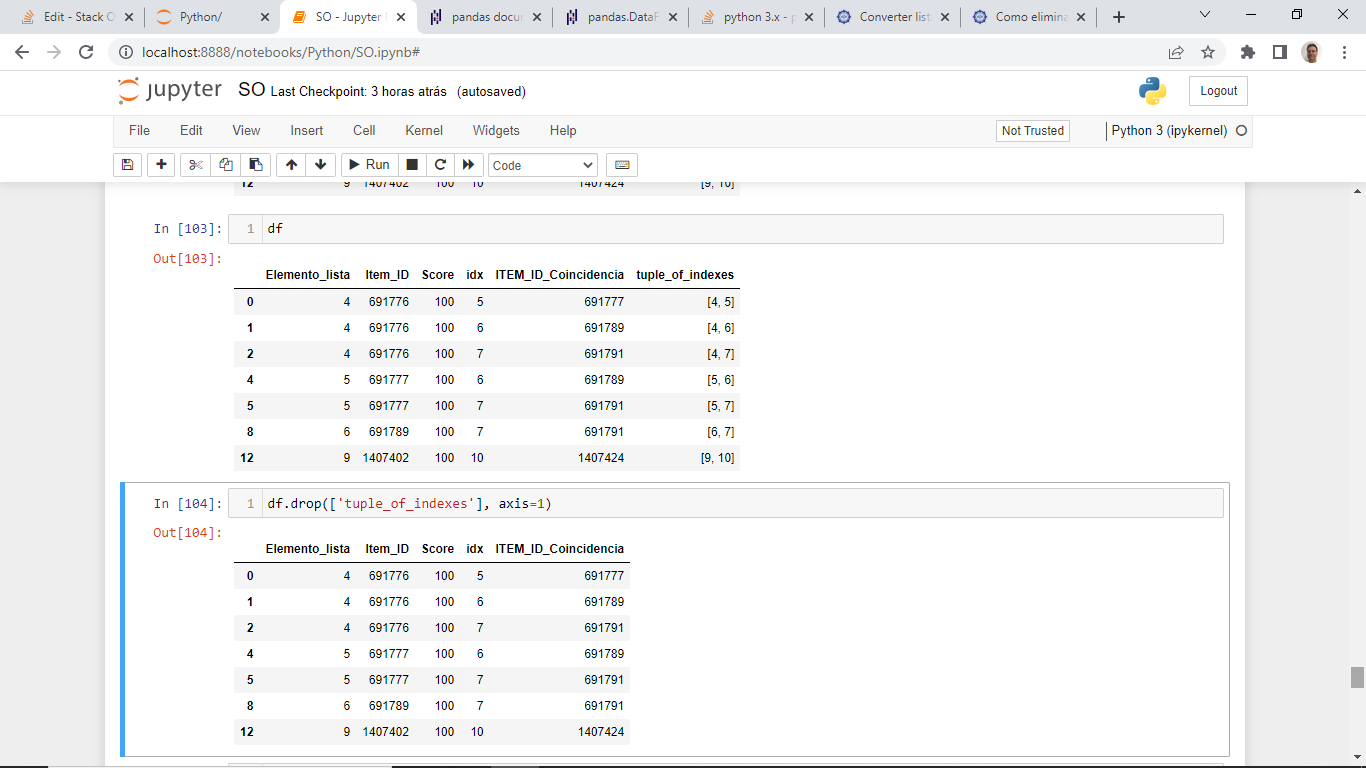
Now, you insert one column: it will contain an array of 2 sorted indexes.
tuples_of_indexes = [sorted([x[0], x[3]]) for x in df.values]
df.insert(5, 'tuple_of_indexes', (tuples_of_indexes))
Then all the dataframe is sorted by the inserted column:
df = df.sort_values(by=['tuple_of_indexes'])
Then you eliminate rows that repeat inserted column:
df = df[~df['tuple_of_indexes'].apply(tuple).duplicated()]
For last, you eliminate inserted column: 'tuple_of_indexes':
df.drop(['tuple_of_indexes'], axis=1)
The output is:
Elemento_lista Item_ID Score idx ITEM_ID_Coincidencia
0 4 691776 100 5 691777
1 4 691776 100 6 691789
2 4 691776 100 7 691791
4 5 691777 100 6 691789
5 5 691777 100 7 691791
8 6 691789 100 7 691791
12 9 1407402 100 10 1407424
CodePudding user response:
This can be approached using graph theory.
You have the following relationships between your IDs:
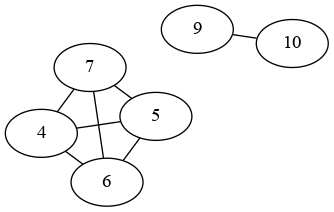
So what you need to do is find the subgraphs.
For this we can use 
You can change strategy here and use a directed graph and 