I want to write a function that replace all zeros with the mean of each customer category.
for example (before):
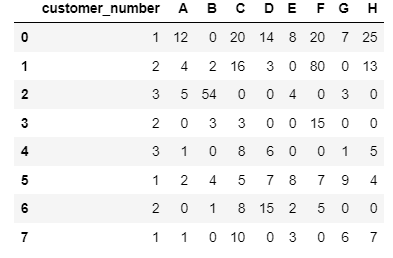
After:
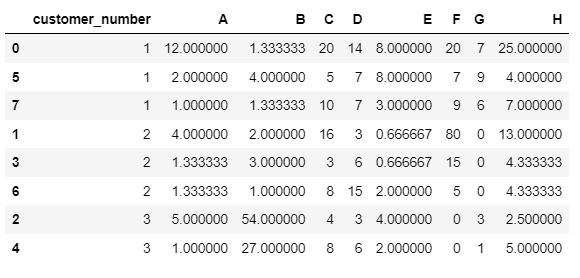
I tried the below code:
df = pd.DataFrame({"customer_number":[1,2,3,2,3,1,2,1],"A":[12, 4, 5, 0, 1,2,0,1],
"B":[0, 2, 54, 3, 0,4,1,0],
"C":[20, 16, 0, 3, 8,5,8,10],
"D":[14, 3, 0, 0, 6,7,15,0],
"E":[8, 0, 4, 0, 0,8,2,3],
"F":[20, 80, 0, 15, 0,7,5,0],
"G":[7, 0, 3, 0, 1,9,0,6],
"H":[25, 13,0, 0, 5,4,0,7]})
df
df.replace(0,df.mean(axis=0),inplace=True)
df
This gives the mean for the entire column with no conditional of customer category.
CodePudding user response:
You can use:
df2 = df.mask(df.eq(0))
df2.combine_first(df
.groupby('customer_number')
.mean()
.reindex(df['customer_number'])
.reset_index()
)
Output:
customer_number A B C D E F G H
0 1 12.000000 1.333333 20.0 14.0 8.000000 20.0 7.0 25.000000
1 2 4.000000 2.000000 16.0 3.0 0.666667 80.0 0.0 13.000000
2 3 5.000000 54.000000 4.0 3.0 4.000000 0.0 3.0 2.500000
3 2 1.333333 3.000000 3.0 6.0 0.666667 15.0 0.0 4.333333
4 3 1.000000 27.000000 8.0 6.0 2.000000 0.0 1.0 5.000000
5 1 2.000000 4.000000 5.0 7.0 8.000000 7.0 9.0 4.000000
6 2 1.333333 1.000000 8.0 15.0 2.000000 5.0 0.0 4.333333
7 1 1.000000 1.333333 10.0 7.0 3.000000 9.0 6.0 7.000000
CodePudding user response:
Use GroupBy.transform for means per groups and replace missing values by DataFrame.mask:
df = df.mask(df.eq(0), df.groupby('customer_number').transform('mean'))
print (df)
customer_number A B C D E F G H
0 1 12.000000 1.333333 20 14 8.000000 20 7 25.000000
1 2 4.000000 2.000000 16 3 0.666667 80 0 13.000000
2 3 5.000000 54.000000 4 3 4.000000 0 3 2.500000
3 2 1.333333 3.000000 3 6 0.666667 15 0 4.333333
4 3 1.000000 27.000000 8 6 2.000000 0 1 5.000000
5 1 2.000000 4.000000 5 7 8.000000 7 9 4.000000
6 2 1.333333 1.000000 8 15 2.000000 5 0 4.333333
7 1 1.000000 1.333333 10 7 3.000000 9 6 7.000000
CodePudding user response:
This code does it for me.
df = df.astype('float') # converting the dataframe to float
for i in df.columns[1:]: # looping over the columns
mean = df.groupby(['customer_number'])[i].mean() # saving the mean of each category for each column
for index,element in enumerate(df[i]): # iterating over the individual column
if element == 0: # replacing only the observations that are 0
cust_numb = df.customer_number[index] # getting the mean of the corresponding category
df[i][index] = mean[cust_numb] # replacing the observation