I'm trying crop an image using opencv and then let tesseract read it, but even the image is quite clear it is not able to recognize numbers out of that image, here are lines of code for the action:
screen_img = cv2.imread(f'data\\screenshot\\{e_name}.png')
crop_img = screen_img[350:385,185:270]
crop_img = cv2.cvtColor(crop_img,cv2.COLOR_BGR2GRAY)
cv2.imwrite(f'data\\screenshot{e_name}.png',crop_img)
cv2.imshow('ad',crop_img)
cv2.waitKey(0)
text = pytesseract.image_to_string(crop_img)
print(text)
The output of cv2.imshow('ad',crop_img) look something like this:
But the output of print(text) is nothing other a new blank line in the console.
I really appreciate for your help (I may making silly mistake since i'm not a professional programmer, then i'm sorry about that).
EDIT1: I've added a few line thanks to the comments:
screen_img = cv2.imread(f'data\\screenshot\\{e_name}.png')
crop_img = screen_img[350:385,185:270]
crop_img = cv2.cvtColor(crop_img,cv2.COLOR_BGR2GRAY)
crop_img = cv2.bitwise_not(crop_img)
ret, thresh1 = cv2.threshold(crop_img, 120, 255, cv2.THRESH_BINARY cv2.THRESH_OTSU)
cv2.imshow('ad',thresh1)
cv2.waitKey(0)
text = pytesseract.image_to_string(thresh1)
The output now look much more promising: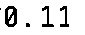
But the result seem to remain the same,i've check some random text image from the internet and most of them work just fine.
CodePudding user response:
A magic happens when adding config='--psm 6'.
According to Tesseract OCR options page:
6 Assume a single uniform block of text.
Code sample:
crop_img = cv2.imread('crop_img.png')
text = pytesseract.image_to_string(crop_img, config='--psm 6')
print(text)
Result:
73.9