I have a dataframe (full) like this:
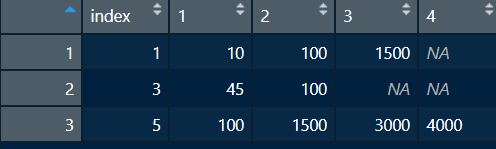
obtained by merging a list of numeric ID codes and a dataframe (reproducible example):
library(plyr)
library(dplyr)
#Create example list: ID codes
l1 <- c(10, 100, 1500)
l2 <- c(45, 100)
l3 <- c(100, 1500, 3000, 4000)
l <- list(l1, l2, l3)
#Convert list into dataframe
ldf <- ldply(l, rbind)
#Create example dataframe
i <- data.frame(index = c(1, 3, 5))
#Merge the two dataframes
full <- merge(i, ldf, by = 'row.names', all = TRUE) %>% select(-Row.names)
I would like to reshape the dataframe as follows:
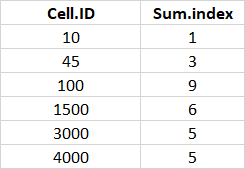
in order to get the sum of the index values for each ID code.
Any idea??
CodePudding user response:
in Base R, we can aggregate the values once we stack them:
aggregate(index~values, cbind(full['index'],stack(full,-1)), sum)
values index
1 10 1
2 45 3
3 100 9
4 1500 6
5 3000 5
6 4000 5
Using tidyverse:
library(tidyverse)
full %>%
pivot_longer(-index, values_drop_na = TRUE) %>%
group_by(value) %>%
summarise(sum_index = sum(index))
# A tibble: 6 x 2
value sum_index
<dbl> <dbl>
1 10 1
2 45 3
3 100 9
4 1500 6
5 3000 5
6 4000 5
CodePudding user response:
Here is a data.table approach:
library(data.table)
melt(setDT(full),id="index",na.rm=T)[, .(Sum.index = sum(index)), by=.(Cell.ID=value)]
Output:
Cell.ID Sum.index
1: 10 1
2: 45 3
3: 100 9
4: 1500 6
5: 3000 5
6: 4000 5