Context:
I have the Plantcube file which has 7 columns and that file is generated by the response of some device and every second that device response temperature or humidity and cube_id and timestamp is by default kind of thing never missed in all 400k records...
Question:
I want to find the count of ids where the device sends a response without temperature or humidity, finding id and their count will help me to trace cubes which having problems sending the response.
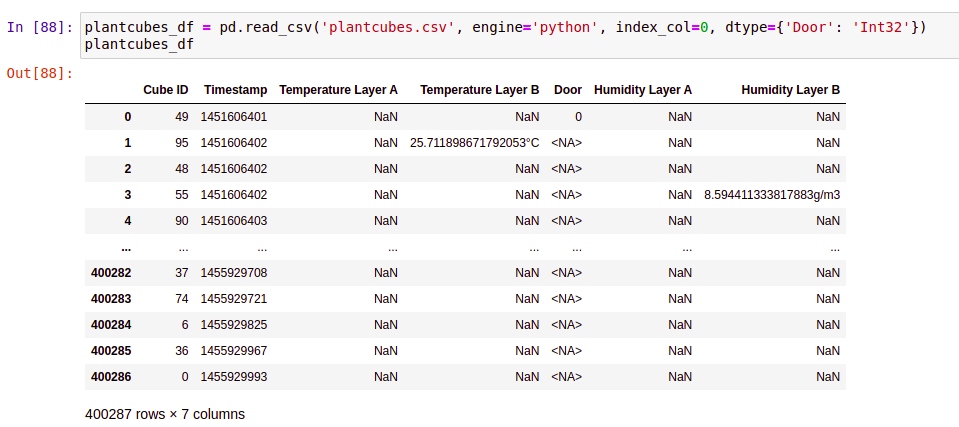
If you look at row no 3 Cube ID 48 and row no 5 Cube ID 90 does not have any information, so I want to count how many times id 48, 90, and others have the same situation.
Expected output eg:
Cube ID -> Missing Count
48 -> 1030
90 -> 790
400286 -> 36
File link : https://drive.google.com/file/d/1xZST8n27IcVsFor1qqu90jZ1E2cJ6pHb/view?usp=sharing
Thanks
CodePudding user response:
df.loc[df.drop('CubeID',axis=1).isna().all(1)]['CubeID'].value_counts()
CodePudding user response:
mask1 = df['Temperature Layer A'].isna()
mask2 = df['Temperature Layer B'].isna()
mask3 = df['Humidity Layer A'].isna()
mask4 = df['Humidity Layer B'].isna()
df[mask1 & mask2 & mask3 & mask4]['Cube ID'].value_counts()
Output:
16 1564
20 1561
45 1561
75 1560
21 1560
...
70 1537
40 1537
37 1536
10 1533
46 613