I want to rank 'drug_name' as per the order of 'svcdate' for each 'patient_id'.
I have attached sample desired output in the image,
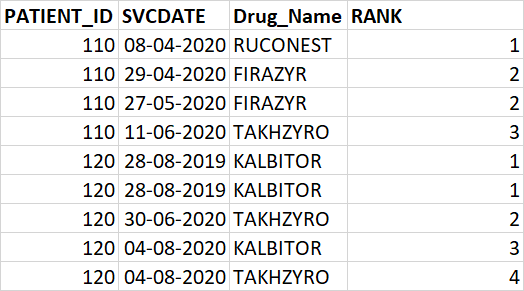
To do so I've tried using the following query,
select *,
dense_rank() over(partition by PATIENT_ID,drug_name order by PATIENT_ID) as rnk
from table
order by PATIENT_ID, svcdate;
Although it's not giving me the output which is mentioned in the image. Please help me to get the desired output. Thanks!!
CodePudding user response:
I think you are really close already. You want your rank to only reset to 1 when encountering a new patient_id, so only include that in your partition by. Then order your ranking by svcdate, to get them in date order, and lastly by drug name. This will rank the same drug filled multiple times on the same date as equals.
select *,
dense_rank() over(partition by PATIENT_ID order by svcdate, drug_name) as rnk
from table
order by PATIENT_ID, svcdate;
CodePudding user response:
This answer is using Snowflake syntax, it might run on other system.
One way to read:
I want to rank 'drug_name' as per the order of 'svcdate' for each 'patient_id'.
implies:
,dense_rank() over(partition by patient_id order by svcdate) as rank
but that gives:
| PATIENT_ID | SVCDATE | DRUG_NAME | RANK |
|---|---|---|---|
| 110 | 2020-04-08 | RUCONEST | 1 |
| 110 | 2020-04-29 | FIRAZYR | 2 |
| 110 | 2020-05-27 | FIRAZYR | 3 |
| 110 | 2020-06-11 | TAKHZYRO | 4 |
| 120 | 2019-08-04 | TAKHZYRO | 1 |
| 120 | 2019-08-28 | KALBITOR | 2 |
| 120 | 2019-08-28 | KALBITOR | 2 |
| 120 | 2020-06-30 | TAKHZYRO | 3 |
| 120 | 2020-08-04 | KALBITOR | 4 |
but if we rank the drug name by their first/earliest svcdate for each patient_id:
we can use:
select patient_id
,svcdate
,drug_name
,dense_rank() over(partition by patient_id order by first_date) as rank
from (
select *
,first_value(svcdate) over (
partition by patient_id, drug_name
order by svcdate) as first_date
from data
)
order by 1,2;
which gives:
| PATIENT_ID | SVCDATE | DRUG_NAME | RANK |
|---|---|---|---|
| 110 | 2020-04-08 | RUCONEST | 1 |
| 110 | 2020-04-29 | FIRAZYR | 2 |
| 110 | 2020-05-27 | FIRAZYR | 2 |
| 110 | 2020-06-11 | TAKHZYRO | 3 |
| 120 | 2019-08-04 | TAKHZYRO | 1 |
| 120 | 2019-08-28 | KALBITOR | 2 |
| 120 | 2019-08-28 | KALBITOR | 2 |
| 120 | 2020-06-30 | TAKHZYRO | 1 |
| 120 | 2020-08-04 | KALBITOR | 2 |
These results match for patient 110, but for 120, you have the same two drugs split almost over years:
so if we use:
select patient_id
,svcdate
,drug_name
,dense_rank() over(partition by patient_id order by first_date) as rank
from (
select *
,first_value(svcdate) over
(partition by patient_id, drug_name, year(svcdate)
order by svcdate) as first_date
from data
)
order by 1,2;
| PATIENT_ID | SVCDATE | DRUG_NAME | RANK |
|---|---|---|---|
| 110 | 2020-04-08 | RUCONEST | 1 |
| 110 | 2020-04-29 | FIRAZYR | 2 |
| 110 | 2020-05-27 | FIRAZYR | 2 |
| 110 | 2020-06-11 | TAKHZYRO | 3 |
| 120 | 2019-08-04 | TAKHZYRO | 1 |
| 120 | 2019-08-28 | KALBITOR | 2 |
| 120 | 2019-08-28 | KALBITOR | 2 |
| 120 | 2020-06-30 | TAKHZYRO | 3 |
| 120 | 2020-08-04 | KALBITOR | 4 |
which now matches both patients.