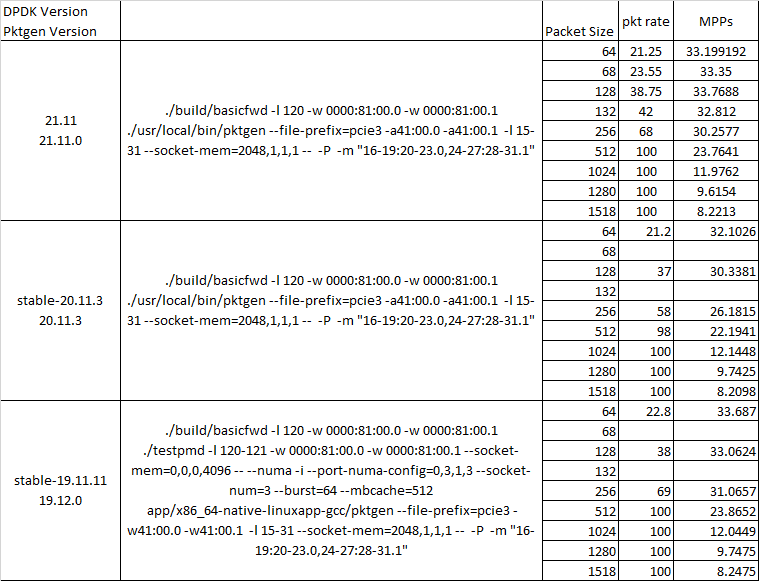
For my measurements, there are two machines, one as client node(Haswell),the other one as server node(Skylake),and both nodes with the NIC,mellanox connect5. client sends packets to the server at a high rate(Gpps), and a simple application -- L2 forwarding, running on the server node with 4096 RX descriptors. I have sent many sizes of packets(64B,128B,256B,512B,1024B,1500B) ,however I get a interesting result. When I send the 128B packets, the latency(both LAT99 and LAT-AVG) is much better than other sizes packets.
There are my measurements results below:
| packet size | THROUGHPUT | PPS | LAT99 | LATAVG |
|---|---|---|---|---|
| 64B | 14772199568.1 | 20983238.0228 | 372.75 | 333.28 |
| 128B | 22698652659.5 | 18666655.1476 | 51.25 | 32.92 |
| 256B | 27318589720 | 12195798.9821 | 494.75 | 471.065822332 |
| 512B | 49867099486 | 11629454.1712 | 491.5 | 455.98037273 |
| 1024B | 52259987845.5 | 6233300.07701 | 894.75 | 842.567256665 |
| 1500B | 51650191179.9 | 4236400.1952 | 1298.5 | 1231.18194373 |
some settings and configuration:
sudo mlxconfig -d 0000:18:00.1 q
The server node(Skylake) is enable DDIO,so the packets are sent directly to the L3 cache. The latency gap between 333.28 and 32.92 is similar to the gap between L1 cache and L3 cache. So, I guess it might be due to L1 prefetch. L1 cache prefetches better, when receives 128B packets than other size packets.
My question:1.Is my guess correct? 2.Why is it faster to process 128B packets, is there any specific L1 prefetch strategy that can explain this result? 3. If my guess is wrong, what is causing this phenomenon?
CodePudding user response:
@xuxingchen there are multiple questions and clarifications required to address the questions. So let me clarify step by step
- Current setup is listed as Mellznox Connectx 5, but
mlxconfigstates it is DPU. DPU has internal engine and Latency will be different foundational NIC from Mellanox such as MLX-4, MLX-5, ConnectX-6. - PCIe read size is recommended to be updated to read size of