I would like some help if possible as I am new to R in filtering after a certain date and then summing the results.
For example, we have these organisations:
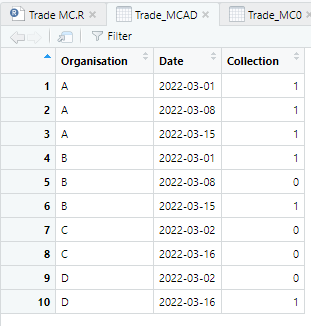
And in these organisations I want to know the consecutive sum of the recent 1's.
For example - A would Return 3 - B would return 1 and C would return 0 and D would also return 1.
The reason being for i.e. B is the most recent date was a 1 - failure but the week before was a success.
I have made some code to pull out the max date of the last 0 (pass) and have this saved in a different DF:
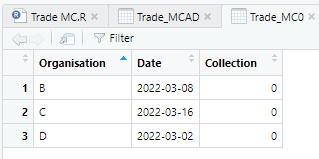
How would I apply this filter (second image/df) to my first dataframe only keeping the most recent dates i.e. the most recent consecutive 1's.
Or if there is a better way to tell r to read the most recent date and add columns until it hits a 0 column by row that would also be appreciated. I tried to have it count the highest consecutive numbers but if the dataframe was other a bigger time period, it would only show the largest failings in the past and I only need the most recent data.
I am new to this so any feedback in language or this query would be appreciated.
My current Code:
Trade_MCAD <- read_excel ("C:/Users/FiercePC/OneDrive/Desktop/Dates MS3 KPI Example/Trade/missed bin.xlsx", sheet=3)
Trade_MCAD$Date <- as.Date(Trade_MCAD$Date)
Trade_MCMaxD <- Trade_MCAD %>%
group_by(Organisation) %>%
filter(Date == max(Date))
Trade_MC0 <- Trade_MCAD[!grepl("1", Trade_MCAD$Collection),]
Trade_MC0 <- Trade_MC0 %>%
group_by(Organisation) %>%
filter(Date == max(Date))
CodePudding user response:
Here is an alternative approach:
library(dplyr)
df %>%
group_by(Organisation) %>%
mutate(x = sequence(rle(as.character(Collection))$lengths)) %>%
summarise(y = ifelse(max(Collection)==1, max(x), min(Collection)))
Organisation y
<chr> <int>
1 A 3
2 B 1
3 C 0
4 D 1
data:
structure(list(Organisation = c("A", "A", "A", "B", "B", "B",
"C", "C", "D", "D"), Date = c("2022-03-01", "2022-03-08", "2022-03-15",
"2022-03-01", "2022-03-08", "2022-03-15", "2022-03-02", "2022-03-16",
"2022-03-02", "2022-03-16"), Collection = c(1L, 1L, 1L, 1L, 0L,
1L, 0L, 0L, 0L, 1L)), class = "data.frame", row.names = c("1",
"2", "3", "4", "5", "6", "7", "8", "9", "10"))
CodePudding user response:
There may be more elegant solutions, but one option is to create variable with the number of repeating instances, the take the last one:
Since you didnt provide reproducible data, here is some similar sample data (edited to use TarJae's more accurate data):
df <- structure(list(Organisation = c("A", "A", "A", "B", "B", "B",
"C", "C", "D", "D"), Date = c("2022-03-01", "2022-03-08", "2022-03-15",
"2022-03-01", "2022-03-08", "2022-03-15", "2022-03-02", "2022-03-16",
"2022-03-02", "2022-03-16"), Collection = c(1L, 1L, 1L, 1L, 0L,
1L, 0L, 0L, 0L, 1L)), class = "data.frame", row.names = c("1",
"2", "3", "4", "5", "6", "7", "8", "9", "10"))
Code:
# generate counts of sequential repeats
df$count <- sequence(rle(as.character(df$Collection))$lengths)
# recode counts for those with collection == 0
df$count <- ifelse(df$Collection == 0, 0, df$count)
# select the last date with collection
df %>% group_by(Organisation) %>%
filter(Collection == 1 | all(Collection == 0)) %>%
slice(n())
Output:
# Organisation Date Collection count
# <chr> <chr> <int> <dbl>
# 1 A 2022-03-15 1 3
# 2 B 2022-03-15 1 1
# 3 C 2022-03-16 0 0
# 4 D 2022-03-16 1 1