I have a dataframe that looks like this one (one column has multiple values, the other are just numbers with decimals):
food number
apple,tomato,melon 897.0
apple,meat,banana 984.9
banana,tomato 340.8
I want to get the average number of every food. In the example that'll be:
- apple = (897.0 984.9)/2 = 940.95
- banana = (984.9 340.8)/2 = 662.85
And so on to the point of ending up with a new dataframe with just the foods and the average number.
food average
apple 915.95
banana 662.85
I tried my luck with groupby, but the result is all messed up:
#reshape data
df = pd.DataFrame({
'food' : list(chain.from_iterable(df.food.tolist())),
'number' : df.number.repeat(df.food.str.len())
})
# groupby
df.groupby('food').number.apply(lambda x: x.unique().tolist())
I must say that the original dataframe has over 100k rows. Thanks.
CodePudding user response:
Use 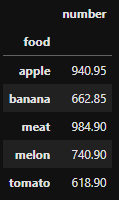
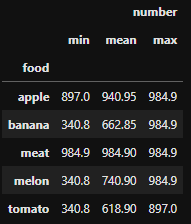
If you would like more aggregations, you could use
df.explode('food').groupby('food').agg(['min', 'mean', 'max'])