Despite having managed to plot a multiple slope plot with fake data (See reproducible example below), I am having troubles managing to adapt the code to my real data, and keep facing errors due to key redundancy.
First, some context: I have a dataset with numerous "_x" and "_y" variables, which are measures at time 1 and 2 -recorded in a column, since each entry has a time1 and a time2- and I would like to plot my slopes for each individual, making a plot for each variable (pair of variables).
I have managed -with some help- to do it for one set of variables in the following reproducible example with no "_x" or "_y" colnames. Yet when I try to adapt this code with selects -in order to just take those columns instead of all the dataset-, changing the colnames to mimic the example, changing the regex etc. etc. I keep facing errors of keys redundancy.
"Error in
spread():
! Each row of output must be identified by a unique combination of keys.
Keys are shared for 195 rows:"
I suspect that this is cause I do have some values in my data that are the same, but with the column ID it shouldn't be a problem and I don't quite grasp what can I do to solve it.
The foo example:
library(tidyverse)
Id <- rep(1:10)
a = c(5,10,15,12,13,25,12,13,11,9)
b = c(8,14,20,13,19,29,15,19,20,11)
c = c(10,14,20,1.5,9,21,13,21,11,10)
d = c(15,9,20,14,12,5,12,13,12,30)
group = as.factor( rep(1:2,each=5) )
data = data.frame(Id,a,b,c,d,group)
case_mapping <- data.frame(
key = c("a", "b", "c", "d"),
key2 = c("x1", "x2", "y1", "y2")
)
data %>%
gather(key, val, c(a:d)) %>%
left_join(case_mapping, by = "key") %>%
select(-key) %>%
extract(key2, into = c("key", "order"), "([a-z])([0-9])") %>%
spread(key, val) %>%
ggplot()
aes(x, y, group = Id, color = group) xlab("Age") #ggtitle(paste("Variable")
geom_point()
geom_line()
And now a example of my data.
library(tidyverse)
Id <- rep(1:10)
var1_x = c(5,10,15,12,13,25,12,13,11,9)
var2_x = c(8,14,20,13,19,29,NA,19,20,11) # just adding some nas.
var3_x = c(10,14,20,1.5,9,21,13,21,11,10)
var1_y = var1_x 3
var2_y = var2_x*2
var3_y = c(10,14,20,1.5,9,21,13,21,11,10) #same, just to see.
age1 = c(15,9,20,14,12,5,12,13,12,30)
age2 = c(18,19,24,16,15,9,16,19,14,37)
group = as.factor( rep(1:2,each=5) )
data = data.frame(Id,var1_x,var2_x,var3_x, var1_y,var2_y,var3_y,age1,age2,group)
Now, should I create a for loop, so I can pair the variables correctly. First we create two strings with the colnames _x and _y
sub_x = colnames(data)[2:4] # sub x
sub_y = colnames(data)[5:7] # suby
And now we should be able to implement the for loop.
for( i in 1:length(sub_x)) {
# We define the matching keys.
case_mapping <- data.frame(
key = c(sub_x[i],sub_y[i], "age1", "age2"),
key2 = c("x1", "x2", "y1", "y2")
)
# And now we should be able to plot this.
data %>%
gather(key, val, c(!!sym(sub_x[i]), !!sym(sub_y[i]), age1,age2 )) %>%
left_join(case_mapping, by = "key") %>%
select(-key) %>%
extract(key2, into = c("key", "order"), "([a-z])([0-9])") %>%
spread(key, val) %>%
ggplot()
aes(x, y, group = Id, color = group)
xlab("Age")
geom_point()
geom_line()
}
Yet this doesn't give me any results and when I try to tweak it it throws errors due to the gather. I hope you can enlighten me in order to understand what I am doing wrong.
PD: Sorry if I'm not fully grammatically correct, but English is my second language.
Edit to clarify:
I intend to plot something like this for every variable -and if there is a way to indicate the ID to each slope that would be really nice so I don't have to look it up from the data to see to which they correspond)
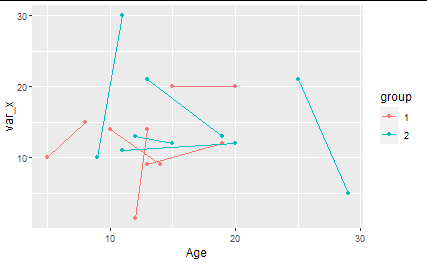
EDIT 2 With the help of Tjebo I somewhat "solve it" but I still need to automatize via dplyr the construction of this data_long2 from the data_long1 provided.
data_long2 <- data.frame( Id = rep(data_long$Id,2), Group = rep(data_long$group,2), Var= rep(data_long$var,2) , Valueage= c(data_long$age1,data_long$age2), Valuevar= c(data_long$x,data_long$y) )
ggplot(data_long2)
## I've removed the grouping by ID, because there was only one observation per ID
aes(Valueage, Valuevar, color=Id)
geom_point()
geom_line(aes(group = Id))
# geom_line()
## you can for example facet by your new variable column
facet_grid(~Var)
#> Warning: Removed 1 rows containing missing values (geom_point).
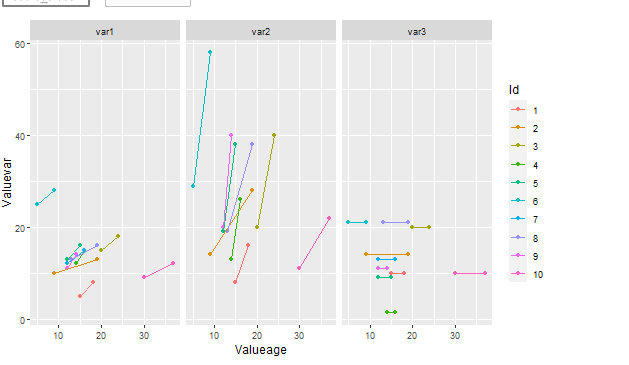
And changing color to group 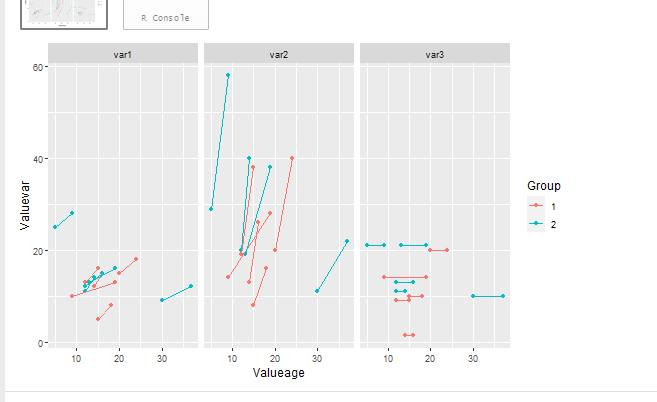
CodePudding user response:
I think you might be overcomplicating things. As far as I understand, you struggle with reshaping your data and then plotting all variables, correct?
Below one approach that makes use of the new-ish pivot_longer for reshaping (it has amazing functionality especially with regards to "multiple gatherings") and then faceting instead of looping.
Update
You basically need to pivot longer twice
library(tidyverse)
Id <- rep(1:10)
var1_x = c(5,10,15,12,13,25,12,13,11,9)
var2_x = c(8,14,20,13,19,29,NA,19,20,11) # just adding some nas.
var3_x = c(10,14,20,1.5,9,21,13,21,11,10)
var1_y = var1_x 3
var2_y = var2_x*2
var3_y = c(10,14,20,1.5,9,21,13,21,11,10) #same, just to see.
age1 = c(15,9,20,14,12,5,12,13,12,30)
age2 = c(18,19,24,16,15,9,16,19,14,37)
group = as.factor( rep(1:2,each=5) )
data = data.frame(Id,var1_x,var2_x,var3_x, var1_y,var2_y,var3_y,age1,age2,group)
data_long <-
data %>%
## make use of the cool pivot_longer function
pivot_longer(cols = matches("_[x|y]"),
names_to = c("var", ".value"),
names_pattern = "(.*)_(.*)") %>%
## now make even longer! all y (currently confusingly called x and y) belong into one column
## and all x (currently called age1 and age2) in another column
## this is easier with a similar pattern in both, therefore renaming
## note the .value name is switched when compared with the first pivoting
rename(y1= x, y2 = y) %>%
pivot_longer(
matches(".*([1-2])"),
names_to = c(".value", "set"),
names_pattern = "(. )([0-9 ])"
)
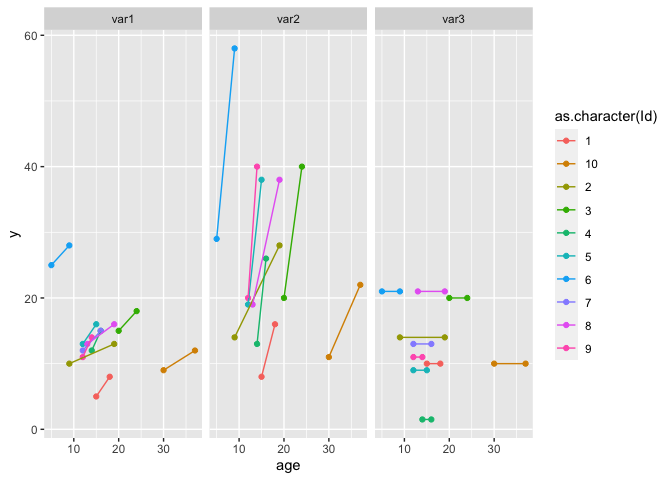
ggplot(data_long)
## I've removed the grouping by ID, because there was only one observation per ID
aes(age, y, color = as.character(Id))
geom_point()
geom_line()
## you can for example facet by your new variable column
facet_grid(~var)
#> Warning: Removed 2 rows containing missing values (geom_point).
To create each plot separately in a loop:
## split by your new variable and run a loop to create a list of plots
ls_p <- lapply(split(data_long, data_long$var), function(.x){
ggplot(.x)
## I've removed the grouping by ID, because there was only one observation per ID
aes(age, y, color = as.character(Id))
geom_point()
geom_line()
## you can for example facet by your new variable column
facet_grid(~var)
} )
## you can then either print them separately or all together, e.g. with patchwork
patchwork::wrap_plots(ls_p) patchwork::plot_layout(ncol = 1)
#> Warning: Removed 2 rows containing missing values (geom_point).
#> Warning: Removed 2 row(s) containing missing values (geom_path).
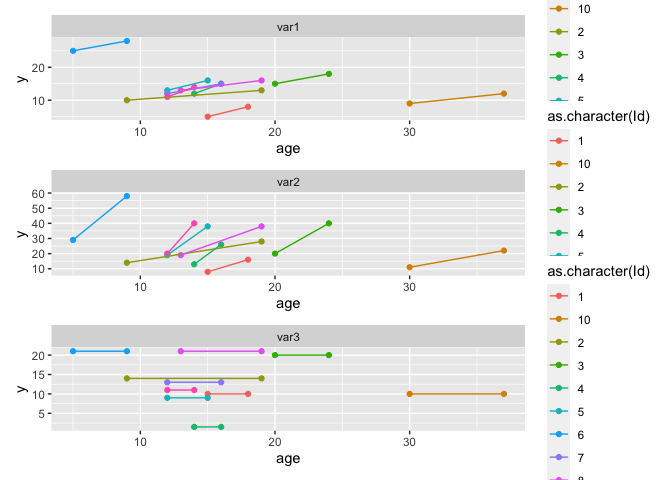
Created on 2022-05-31 by the reprex package (v2.0.1)