I am working on a binary classification and using kernelExplainer to explain the results of my model (logistic regression).
My code is as follows
X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=0.30, random_state=42)
lr = LogisticRegression() # fit and predict statements not shown
masker = Independent(X_train, max_samples=100)
explainer = KernelExplainer(lr.predict,X_train)
bv = explainer.expected_value
sv = explainer.shap_values(X_train)
sdf_train = pd.DataFrame({
'row_id': X_train.index.values.repeat(X_train.shape[1]),
'feature': X_train.columns.to_list() * X_train.shape[0],
'feature_value': X_train.values.flatten(),
'base_value': bv,
'shap_values': sv.values[:,:,1].flatten() #error here I guess
})
But I got the below error first. So, I updated the last line to 'shap_values': pd.DataFrame(sv).values[:,1].flatten() but I got the second error shown below
numpy.ndarray has no attribute values
ValueError: All arrays must be of the same length
wrt to datatypes, my X_train is a dataframe and sv is numpy.ndarray
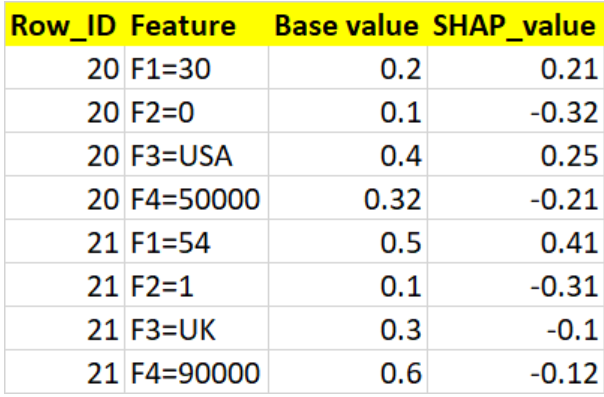
I expect my output to be like as below (ignore the changes in base value. It should be constant). But the output structure is like below
CodePudding user response:
The following will do:
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from shap import KernelExplainer
from shap import sample
X, y = load_breast_cancer(return_X_y=True, as_frame=True)
X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=0.30, random_state=42)
lr = LogisticRegression(max_iter=10000).fit(X_train, y_train)
background = sample(X_train, 100)
explainer = KernelExplainer(lr.predict, background)
sv = explainer.shap_values(X_train)
bv = explainer.expected_value
Note the shape of sv:
sv.shape
(398, 30)
which means:
sdf_train = pd.DataFrame({
'row_id': X_train.index.values.repeat(X_train.shape[1]),
'feature': X_train.columns.to_list() * X_train.shape[0],
'feature_value': X_train.values.flatten(),
'base_value': bv,
'shap_values': sv.flatten() #error here I guess
})
sdf_train
row_id feature feature_value base_value shap_values
0 149 mean radius 13.74000 0.67 0.000000
1 149 mean texture 17.91000 0.67 -0.014988
2 149 mean perimeter 88.12000 0.67 0.060759
3 149 mean area 585.00000 0.67 0.028677