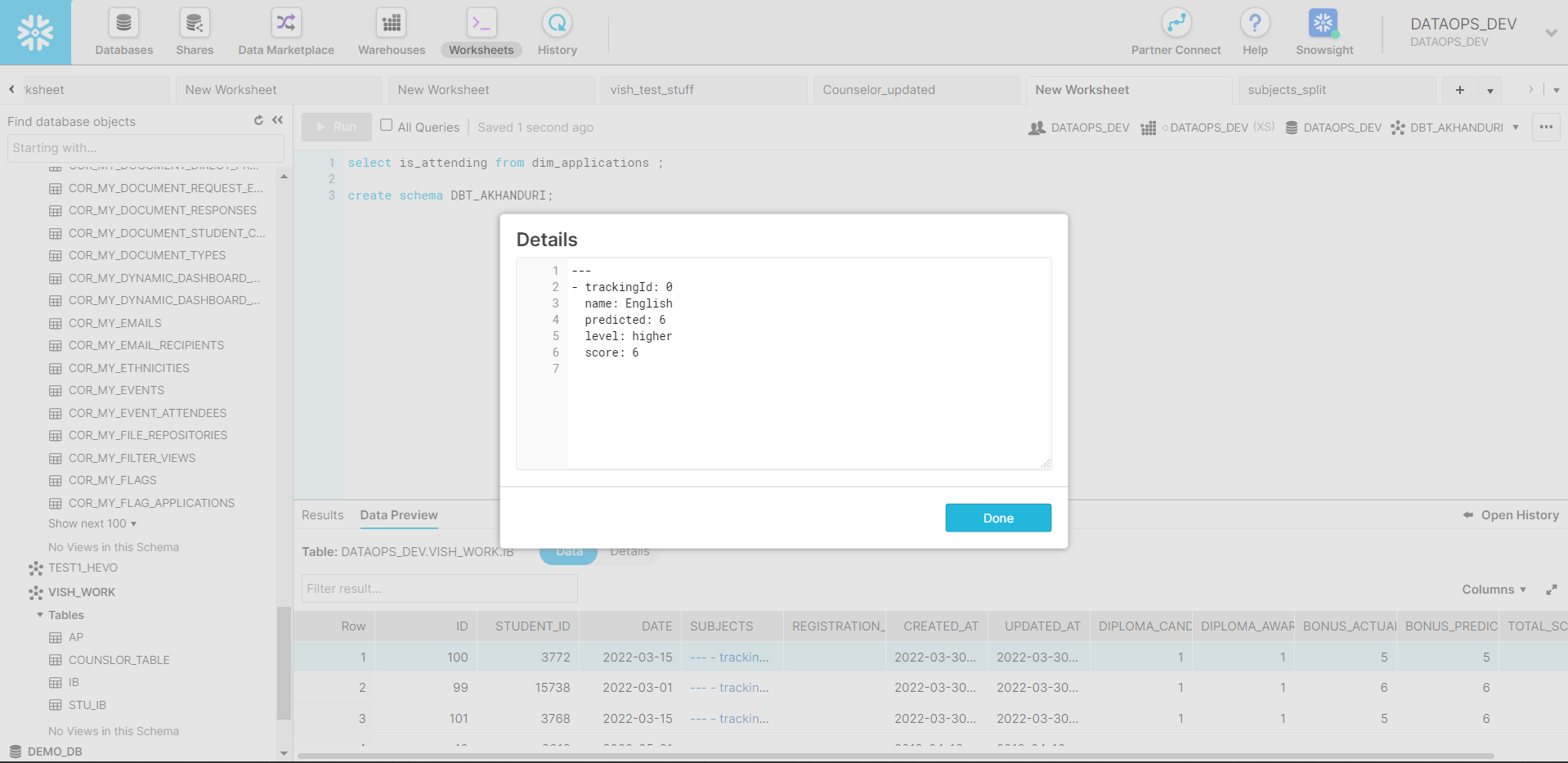
I want to split a json column that has multiple values as shown in the picture below into new columns. I'm using snowflake cause that's where the data is located.
like for example , I want name, predicted, level, score all as new column.
CodePudding user response:
You can use the DOC to flatten the JSON data into different columns.
CodePudding user response:
So with this CTE to provide the input/data:
with data as (
SELECT '---
- trackingId: 0
name: English
predicated: 6
level: higher
score: 6' as subjects
)
lets strip that in parts:
select d.*
,s.seq
,s.value as raw
,trim(trim(s.value,'-'),' ') as trimmed
,split(trimmed,':') as parts
,trim(parts[0]) as key
,trim(parts[1]) as val
,iff(key='name', val,null) as name
,iff(key='predicated', val,null) as predicated
,iff(key='level', val,null) as level
,iff(key='score', val,null) as score
from data as d,
table(split_to_table(d.subjects, '\n')) s
where trimmed <> ''
gives:
| SUBJECTS | SEQ | RAW | TRIMMED | PARTS | KEY | VAL | NAME | PREDICATED | LEVEL | SCORE |
|---|---|---|---|---|---|---|---|---|---|---|
| --- - trackingId: 0 name: English predicated: 6 level: higher score: 6 | 1 | - trackingId: 0 | trackingId: 0 | [ "trackingId", " 0" ] | trackingId | 0 | ||||
| --- - trackingId: 0 name: English predicated: 6 level: higher score: 6 | 1 | name: English | name: English | [ "name", " English" ] | name | English | English | |||
| --- - trackingId: 0 name: English predicated: 6 level: higher score: 6 | 1 | predicated: 6 | predicated: 6 | [ "predicated", " 6" ] | predicated | 6 | 6 | |||
| --- - trackingId: 0 name: English predicated: 6 level: higher score: 6 | 1 | level: higher | level: higher | [ "level", " higher" ] | level | higher | higher | |||
| --- - trackingId: 0 name: English predicated: 6 level: higher score: 6 | 1 | score: 6 | score: 6 | [ "score", " 6" ] | score | 6 | 6 |
So we can then roll that back up:
select seq
,max(name) as name
,max(predicated) as predicated
,max(level) as level
,max(score) as score
from (
select d.*
,s.seq
,trim(trim(s.value,'-'),' ') as trimmed
,split(trimmed,':') as parts
,trim(parts[0]) as key
,trim(parts[1]) as val
,iff(key='name', val,null) as name
,iff(key='predicated', val,null) as predicated
,iff(key='level', val,null) as level
,iff(key='score', val,null) as score
from data as d,
table(split_to_table(d.subjects, '\n')) s
where trimmed <> ''
)
group by seq;
giving:
| SEQ | NAME | PREDICATED | LEVEL | SCORE |
|---|---|---|---|---|
| 1 | English | 6 | higher | 6 |