I wanted to know the how I could plot what I'm seeing in my data.
For context, I have the numerical performance score each individual student has received in 9 different subjects (my snapshot only includes 4 of these). I have this data for around 50 students. One fact that's of interest to me, is whether there is between subject variation for a student in their performance. For example, I want to know if students are either consistently high or low performers across all subjects or if there is some variation in their performance.
How could I plot this?
student_id Math_score English_score Social_studies_score Chemistry_score
42 20 15 16 12
41 23 23 14 18
40 6 12 20 23
32 18 9 23 22
34 15 21 23 21
45 10 8 22 18
39 20 12 18 6
10 23 19 17 14
Thanks!
CodePudding user response:
Here's one approach, just plotting the raw data, but clarifying things by sorting the students by average score.
First I reshape the data long using tidyr::pivot_longer, which puts the data into a format that works better with ggplot2. Then I take the step of changing the student id into an ordered factor in order of mean score across all subjects.
library(tidyverse)
df_long <- df %>%
pivot_longer(-student_id) %>%
mutate(student_id = student_id %>% as.factor %>%
fct_reorder(value, mean) %>% fct_rev)
ggplot(df_long, aes(student_id, value, color = name))
geom_point()
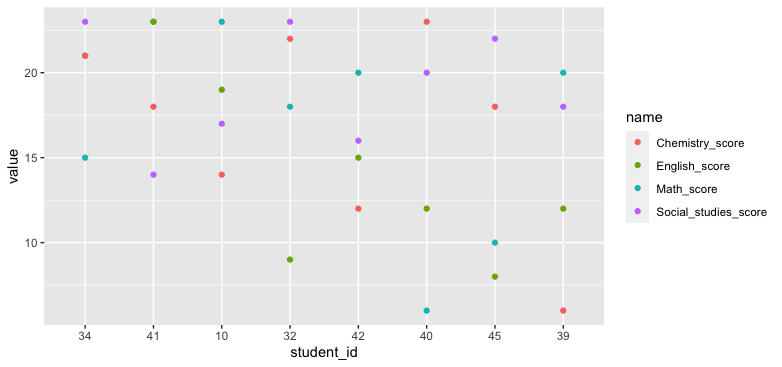
data:
df <- data.frame(
student_id = c(42L, 41L, 40L, 32L, 34L, 45L, 39L, 10L),
Math_score = c(20L, 23L, 6L, 18L, 15L, 10L, 20L, 23L),
English_score = c(15L, 23L, 12L, 9L, 21L, 8L, 12L, 19L),
Social_studies_score = c(16L, 14L, 20L, 23L, 23L, 22L, 18L, 17L),
Chemistry_score = c(12L, 18L, 23L, 22L, 21L, 18L, 6L, 14L)
)
CodePudding user response:
One option that will scale well to more subjects and students is a waffle-style plot:
library(tidyverse)
pivot_longer(df, -1) %>%
mutate(Student = factor(student_id),
Subject = sub(' score', '', gsub('_', ' ', name))) %>%
ggplot(aes(Student, Subject, fill = value))
geom_tile(size = 3, color = 'white')
coord_equal()
labs(fill = 'Score')
scale_fill_viridis_c()
theme_void(base_size = 12)
theme(axis.text = element_text(),
axis.title = element_text(),
axis.text.y = element_text(hjust = 1),
axis.title.y = element_text(angle = 90, size = 20),
axis.title.x = element_text(margin = margin(10, 10, 10, 10),
size = 20),
legend.title = element_text(size = 20),
legend.margin = margin(20, 20, 20, 20))
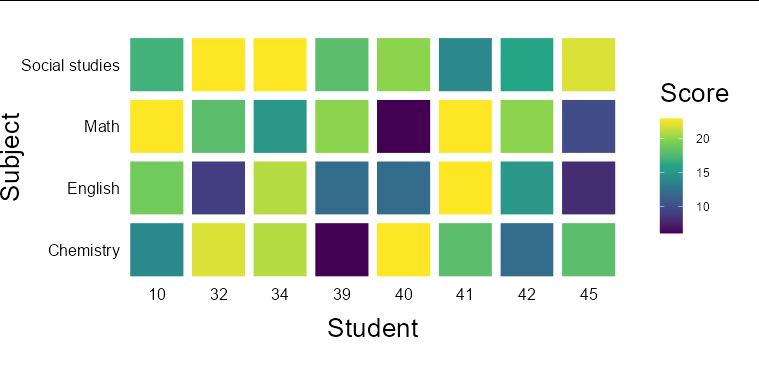
Expanding to 50 students and 10 subjects might look something like this:
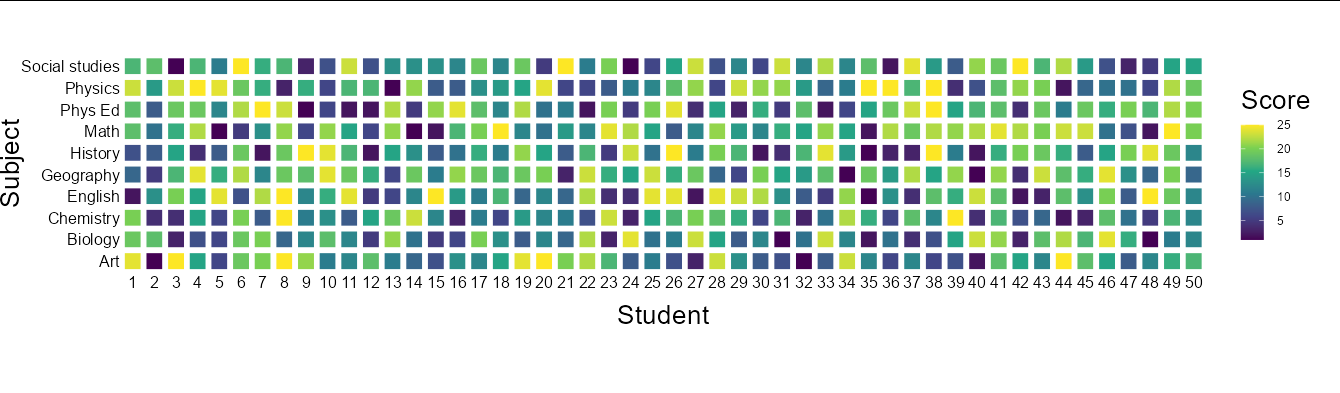
CodePudding user response:
Could use geom_boxplot to show the median and range of scores across subjects by student.
By adding a geom_point layer, you could additionally show the subject scores.
To scale it up to 500 students, I've grouped the students in to 4 quartiles based on their mean scores using cut_interval. You could choose any number of groups.
library(tidyverse)
library(glue)
# Sample data
df <- tibble(
student_id = 1:500,
Math_score = rnorm(500, 23, 1.2),
English_score = rnorm(500, 24, 1.3),
Social_studies_score = rnorm(500, 22, 1.4),
Chemistry_score = rnorm(500, 20, 1.1)
)
# Summarise and plot
df |>
pivot_longer(-student_id, values_to = "score", names_to = "subject") |>
group_by(student_id) |>
mutate(mean_score = mean(score)) |>
ungroup() |>
mutate(quartile = cut_interval(mean_score, n = 4,
labels = c("Bottom Quartile", "Lower Quartile",
"Upper Quartile", "Top Quartile")),
quartile = fct_reorder(quartile, mean_score)) |>
ggplot(aes(quartile, score, group = quartile))
geom_boxplot()
geom_jitter(aes(colour = subject), width = 0.2)
coord_flip()
labs(x = NULL, y = "Score", colour = "Subject",
title = glue("Scores for {nrow(df)} Students"))
theme_bw()
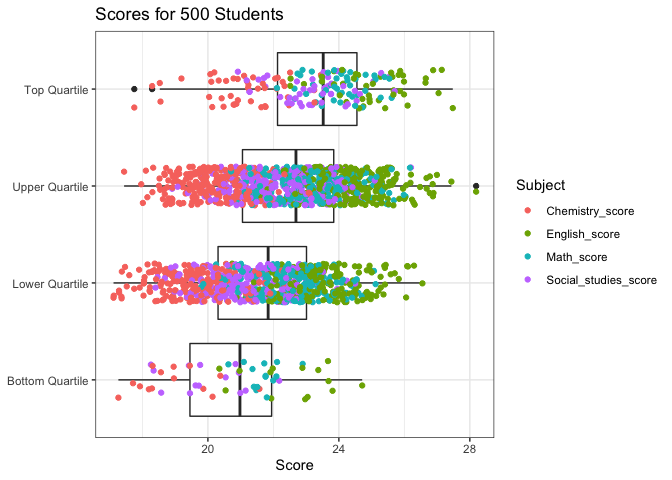
Created on 2022-06-02 by the reprex package (v2.0.1)