For each year in my data frame, I would like to calculate the percentage of birds with (face.data=="yes") out of the total number of birds observed during that year. One problem is that I have multiple observations of the same bird within the same year.
This is my dataset:
df <- data.frame(
bird.ID = c(001, 001, 001, 002, 002, 002, 006 ,006, 007, 007, 007, 007),
date = c(2010-04-09, 2013-04-14, 2013-09-14, 2013-05-08, 2013-06-08, 2013-08-08, 2013-04-08, 2013-06-08, 2014-06-08, 2016-06-08, 2017-06-08, 2017-08-08),
face.data = c("yes", "yes", "no","yes", "yes", "no","yes", "yes", "no","yes", "yes", "no")
)
To get the number of "yes" per year, I tried:
aggregate(face.data=="yes" ~ cut(date, "1 year"), data = df, sum)
But that counts every line with "yes" even if that of the same bird.
Ideally, the end result will be a data freame with three columns: (i) the year (e.g.2013); (ii) the total number of Bird.ID observed that year, (iii) the number of unique bird.ID with face.data=="yes" observed during this year.
Something like this:
year number of bird.ID number of face.data
1 2013 10 3
2 2014 15 6
3 2015 20 9
CodePudding user response:
A dyplrsolution:
df %>%
mutate(date = ymd(date),
Year= year(date)) %>%
group_by(Year) %>%
summarise(total_birds = length(unique(bird.ID)),
yes_birds = length(unique(bird.ID[face.data=='yes'])))
Output:
# A tibble: 5 x 3
Year total_birds yes_birds
<dbl> <int> <int>
1 2010 1 1
2 2013 3 3
3 2014 1 0
4 2016 1 1
5 2017 1 1
Or with n_distinct():
df %>%
mutate(date = ymd(date),
Year= year(date)) %>%
group_by(Year) %>%
summarise(total_birds = n_distinct(bird.ID),
yes_birds = n_distinct(bird.ID[face.data=='yes']))
CodePudding user response:
In a by approach count the respective lengths.
First, some fresh sample data.
# bird.ID date face.data
# 1 4 2008-01-24 no
# 2 5 2008-05-25 no
# 3 4 2008-07-15 no
# 4 2 2008-08-13 yes
# 5 1 2008-09-15 no
# 6 2 2008-10-25 yes
# 7 1 2008-11-09 yes
# 8 2 2009-02-09 no
# 9 2 2009-04-25 yes
# 10 2 2009-05-18 yes
# 11 5 2009-09-12 no
# 12 4 2009-09-17 no
# 13 1 2009-12-27 yes
# 14 4 2010-04-15 no
# 15 1 2010-05-09 no
# 16 3 2010-07-10 yes
# 17 1 2010-08-02 no
# 18 1 2010-09-08 no
# 19 3 2010-09-10 yes
# 20 1 2010-09-23 no
by(dat, cut(dat$date, "1 year"), \(x)
with(x, c(year=as.integer(strftime(date[[1]], '%Y')),
`number of bird.ID`=length(unique(bird.ID)),
`number of face.data`=length(unique(bird.ID[face.data == 'yes']))))) |>
do.call(what=rbind) |> `rownames<-`(NULL) |> as.data.frame()
# year number of bird.ID number of face.data
# 1 2008 4 2
# 2 2009 4 2
# 3 2010 3 1
Data:
n <- 20
set.seed(42)
dat <- data.frame(bird.ID=sample(1:5, n, replace=TRUE),
date=sample(seq.Date(as.Date('2008-01-01'), as.Date('2011-01-01'), 'day'), n, replace=TRUE),
face.data=sample(c('yes', 'no'), n, replace=TRUE))
CodePudding user response:
Using data.table:
dt <- data.table(df)
unique(dt[, .(bird.ID, year = year(date), face.data)])[
, .(`number of bird.ID` = length(unique(bird.ID)),
`number of face.data` = sum(face.data=="yes")),
by=.(year)]
year number of bird.ID number of face.data
1: 2010 1 1
2: 2013 3 3
3: 2014 1 0
4: 2016 1 1
5: 2017 1 1
CodePudding user response:
You can fix the problem quickly by using a little function:
yes_prop<-function(x)
{
number_of_bird.ID<-length(unique(x$bird.ID)) # number of unique bird.IDs
number_of_face.data<-length(unique(x$bird.ID[x$face.data=="yes"])) # setting "yes", number of unique bird.IDs
data.frame(number_of_bird.ID,number_of_face.data)
}
For a simplified dates data.frame:
df <- data.frame(
bird.ID = c(001, 001, 001, 002, 002, 002, 006 ,006, 007, 007, 007, 007),
date = c(2010, 2013, 2013, 2013, 2013, 2013, 2013, 2013, 2014, 2016, 2017, 2017),
face.data = c("yes", "yes", "no","yes", "yes", "no","yes", "yes", "no","yes", "yes", "no")
)
do.call(rbind,by(df,df$date, yes_prop)) # applying function year by year
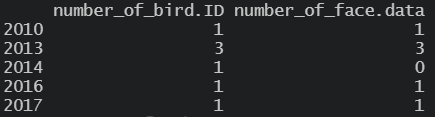
Anyway, I have no doubt smarter solutions could be provided by any other user.