Issue:
I'm a beginner at building classification models, so I am sorry if this question might sound terminologically incorrect. I will try my best. I am having trouble interpreting the error messages that I am receiving when creating a confusion matrix using the e1071 package.
I have tried many solutions to fix the errors but I really can't comprehend how to move further to successfully produce a confusion matrix using the gbm method (see below). I have tried my best to try and fix the error and I feel confused.
Error: `data` and `reference` should be factors with the same levels.
This exercise is part of a university assignment and I would be really grateful if anybody can help me solve this issue and explain what these error messages mean as a learning exercise.
My data has nine continuous independent variables, and one dependent variable called 'Country'.
Another post suggested that:
the error means that you need to give it factors as inputs (train[[predict]] > c is not a factor). Try using factor(ifelse(...), levels) instead).
I'm developing a gbm model using Caret package.
#install packages
library(gbm)
library(caret)
library(e1701)
set.seed(45L)
#Produce a new version of the data frame 'Clusters_Dummy' with the rows shuffled
NewClusters=Cluster_Dummy_2[sample(1:nrow(Cluster_Dummy_2)),]
#Produce a dataframe
NewCluster<-as.data.frame(NewClusters)
#Split the training and testing data 70:30
training.parameters <- Cluster_Dummy_2$Country %>%
createDataPartition(p = 0.7, list = FALSE)
train.data <- NewClusters[training.parameters, ]
test.data <- NewClusters[-training.parameters, ]
dim(train.data)
#259 10
dim(test.data)
#108 10
#Auxiliary function for controlling model fitting
#10 fold cross validation; 10 times
fitControl <- trainControl(## 10-fold CV
method = "repeatedcv",
number = 10,
## repeated ten times
repeats = 10,
classProbs = TRUE)
#Fit the model
gbmFit1 <- train(Country ~ ., data=train.data,
method = "gbm",
trControl = fitControl,
## This last option is actually one
## for gbm() that passes through
verbose = FALSE)
gbmFit1
summary(gbmFit1)
#Predict the model with the test data
pred_model_Tree1 = predict(gbmFit1, newdata = head(test.data$Country), type = "prob")
pred_model_Tree1
print(pred_model_Tree1)
Confusion Matrix
#Confusion Matrix
confusionMatrix(pred_model_Tree1, test.data$Country)
#Error
Error: `data` and `reference` should be factors with the same levels.
What type of objects are pred_model_Tree1 & test.data$Country
typeof(pred_model_Tree1)
#list
typeof(test.data$Country)
#"integer"
#Convert both objects into factors
test.data$Country<-as.factor(test.data$Country)
#check
str(test.data)
'data.frame': 108 obs. of 10 variables:
$ Country : Factor w/ 3 levels "France","Holland",..: 2 1 1 2 1 2 1 1 2 2 ...
#str(pred_model_Tree1)
#data.frame': 6 obs. of 3 variables:
#$ France : num 0.00311 0.98187 0.98882 0.00935 0.99632 ...
#$ Holland : num 9.24e-01 1.41e-03 1.58e-03 4.45e-01 1.86e-05
#$ Spain: num 0.073 0.01672 0.0096 0.54539 0.00366 ...
#Differences:
pred_model_Tree1 (three columns; 6 obs; 3 variables);
test.data (11 columns; 6 obs, dependent variable - 3 levels)
Question: How to transform both objects to follow the same structure and the same levels
#Check the number of rows of the test.data
nrow(test.data)
#108
#Check the number of rows of the predicted output
nrow(pred_model_Tree1)
#6
#What are the levels
levels(pred_model_Tree1)
#NULL
levels(test.data$Country)
#[1] "France" "Holland" "Spain"
table(test.data$Country)
#France Holland Spain
#35 36 37
I found a really good Stackoverflow question here to try and solve the issue and I tried to find a solution
#If you can't get the confusion matrix to work, break it down'
#Error: data and reference data should be factors with the same levels
#confusionMatrix(predicted, actual)
table(pred_model_Tree1) #Predicted
# France Holland Spain
#1 0.003110462 9.238903e-01 0.072999195
#2 0.981868172 1.408983e-03 0.016722845
#3 0.988820237 1.575354e-03 0.009604409
#4 0.009346725 4.452638e-01 0.545389520
#5 0.996322192 1.864682e-05 0.003659161
#6 0.012668621 9.803462e-01 0.006985212
table(test.data$Country) #Actual
#France Holland Spain
#38 46 24
#Great, they both have the same column headings
#Do the predicted and actual data match (are they factors)
confusionMatrix(as.factor(pred_model_Tree1), as.factor(test.data$Country))
#Error in confusionMatrix.default(as.factor(pred_model_Tree1), as.factor(test.data$Country)) :
#The data must contain some levels that overlap the reference.
#In addition: Warning message:
# In xtfrm.data.frame(x) : cannot xtfrm data frames
#format() treats the elements of a vector as character strings using a common format.
pred<-format(round(predict(pred_model_Tree1, test.data)))
#Error
Error in UseMethod("predict") :
no applicable method for 'predict' applied to an object of class "data.frame"
#One answer contained a custom made function
#They suggest that at least one number in the test.data that is never predicted. This is what is meant why "different number of levels".
table(factor(pred_model_Tree1, levels=min(test.data):max(test.data)),
factor(test.data$Country, levels=min(test.data):max(test.data)))
#Error
Error in FUN(X[[i]], ...) :
only defined on a data frame with all numeric-alike variables
#Lastly, I found a function on StackOverflow that can be used to fix the unequal levels problem
# Create a confusion matrix from the given outcomes, whose rows correspond
# to the actual and the columns to the predicated classes.
createConfusionMatrix <- function(act, pred) {
# You've mentioned that neither actual nor predicted may give a complete
# picture of the available classes, hence:
numClasses <- max(act, pred)
# Sort predicted and actual as it simplifies what's next. You can make this
# faster by storing `order(act)` in a temporary variable.
pred <- pred[order(act)]
act <- act[order(act)]
sapply(split(pred, act), tabulate, nbins=numClasses)
}
act<-pred_model_Tree1
pred<-test.data$Country
print(createConfusionMatrix(act, pred))
#Error
Error in FUN(X[[i]], ...) :
only defined on a data frame with all numeric-alike variables
Data
structure(list(Low.Freq = c(435L, 94103292L, 1L, 2688L, 8471L,
28818L, 654755585L, 468628164L, 342491L, 2288474L, 3915L, 411L,
267864894L, 3312618L, 5383L, 8989443L, 1894L, 534981L, 9544861L,
3437614L, 475386L, 7550764L, 48744L, 2317845L, 5126197L, 2445L,
8L, 557450L, 450259742L, 21006647L, 9L, 7234027L, 59L, 9L, 605L,
9199L, 3022L, 30218156L, 46423L, 38L, 88L, 396396244L, 28934316L,
7723L, 95688045L, 679354L, 716352L, 76289L, 332826763L, 6L, 90975L,
83103577L, 9529L, 229093L, 42810L, 5L, 18175302L, 1443751L, 5831L,
8303661L, 86L, 778L, 23947L, 8L, 9829740L, 2075838L, 7434328L,
82174987L, 2L, 94037071L, 9638653L, 5L, 3L, 65972L, 0L, 936779338L,
4885076L, 745L, 8L, 56456L, 125140L, 73043989L, 516476L, 7L,
4440739L, 612L, 3966L, 8L, 9255L, 84127L, 96218L, 5690L, 56L,
3561L, 78738L, 1803363L, 809369L, 7131L, 0L), High.Freq = c(6071L,
3210L, 6L, 7306092L, 6919054L, 666399L, 78L, 523880161L, 4700783L,
4173830L, 30L, 811L, 341014L, 780L, 44749L, 91L, 201620707L,
74L, 1L, 65422L, 595L, 89093186L, 946520L, 6940919L, 655350L,
4L, 6L, 618L, 2006697L, 889L, 1398L, 28769L, 90519642L, 984L,
0L, 296209525L, 487088392L, 5L, 894L, 529L, 5L, 99106L, 2L, 926017L,
9078L, 1L, 21L, 88601017L, 575770L, 48L, 8431L, 194L, 62324996L,
5L, 81L, 40634727L, 806901520L, 6818173L, 3501L, 91780L, 36106039L,
5834347L, 58388837L, 34L, 3280L, 6507606L, 19L, 402L, 584L, 76L,
4078684L, 199L, 6881L, 92251L, 81715L, 40L, 327L, 57764L, 97668898L,
2676483L, 76L, 4694L, 817120L, 51L, 116712L, 666L, 3L, 42841L,
9724L, 21L, 4L, 359L, 2604L, 22L, 30490L, 5640L, 34L, 51923625L,
35544L), Peak.Freq = c(87005561L, 9102L, 994839015L, 42745869L,
32840L, 62737133L, 2722L, 24L, 67404881L, 999242982L, 3048L,
85315406L, 703037627L, 331264L, 8403609L, 3934064L, 50578953L,
370110665L, 3414L, 12657L, 40L, 432L, 7707L, 214L, 68588962L,
69467L, 75L, 500297L, 704L, 1L, 102659072L, 60896923L, 4481230L,
94124925L, 60164619L, 447L, 580L, 8L, 172L, 9478521L, 20L, 53L,
3072127L, 2160L, 27301893L, 8L, 4263L, 508L, 712409L, 50677L,
522433683L, 112844L, 193385L, 458269L, 93578705L, 22093131L,
6L, 9L, 1690461L, 0L, 4L, 652847L, 44767L, 21408L, 5384L, 304L,
721L, 651147L, 2426L, 586L, 498289375L, 945L, 6L, 816L, 46207L,
39135L, 6621028L, 66905L, 26905085L, 4098L, 0L, 14L, 88L, 530L,
97809006L, 90L, 6L, 260792844L, 9L, 833205723L, 99467321L, 5L,
8455640L, 54090L, 2L, 309L, 299161148L, 4952L, 454824L), Delta.Freq = c(5L,
78L, 88553L, 794L, 5L, 3859122L, 782L, 36L, 8756801L, 243169338L,
817789L, 8792384L, 7431L, 626921743L, 9206L, 95789L, 7916L, 8143453L,
6L, 4L, 6363L, 181125L, 259618L, 6751L, 33L, 37960L, 0L, 2L,
599582228L, 565585L, 19L, 48L, 269450424L, 70676581L, 7830566L,
4L, 86484313L, 21L, 90899794L, 2L, 72356L, 574280L, 869544L,
73418L, 6468164L, 2259L, 5938505L, 31329L, 1249L, 354L, 8817L,
3L, 2568L, 82809L, 29836269L, 5230L, 37L, 33752014L, 79307L,
1736L, 8522076L, 40L, 2289135L, 862L, 801448L, 8026L, 5L, 15L,
4393771L, 405914L, 71098L, 950288L, 8319L, 1396973L, 832L, 70L,
1746L, 61907L, 8709547L, 300750537L, 45862L, 91417085L, 79892L,
47765L, 5477L, 18L, 4186L, 2860L, 754038591L, 375L, 53809223L,
72L, 136L, 509L, 232325L, 13128104L, 1692L, 8581L, 23L), Delta.Time = c(1361082L,
7926L, 499L, 5004L, 3494530L, 213L, 64551179L, 70L, 797L, 5L,
72588L, 86976L, 5163L, 635080L, 3L, 91L, 919806257L, 81443L,
3135427L, 4410972L, 5810L, 8L, 46603718L, 422L, 1083626L, 48L,
15699890L, 7L, 90167635L, 446459879L, 2332071L, 761660L, 49218442L,
381L, 46L, 493197L, 46L, 798597155L, 45342274L, 6265842L, 6L,
3445819L, 351L, 1761227L, 214L, 959L, 908996387L, 6L, 3855L,
9096604L, 152664L, 7970052L, 32366926L, 31L, 5201618L, 114L,
7806411L, 70L, 239L, 5065L, 2L, 1L, 14472831L, 122042249L, 8L,
495604L, 29L, 8965478L, 2875L, 959L, 39L, 9L, 690L, 933626665L,
85294L, 580093L, 95934L, 982058L, 65244056L, 137508L, 29L, 7621L,
7527L, 72L, 2L, 315L, 6L, 2413L, 8625150L, 51298109L, 851L, 890460L,
160736L, 6L, 850842734L, 2L, 7L, 76969113L, 190536L), Peak.Time = c(1465265L,
452894L, 545076172L, 8226275L, 5040875L, 700530L, 1L, 3639L,
20141L, 71712131L, 686L, 923L, 770569738L, 69961L, 737458636L,
122403L, 199502046L, 6108L, 907L, 108078263L, 7817L, 4L, 6L,
69L, 721L, 786353L, 87486L, 1563L, 876L, 47599535L, 79295722L,
53L, 7378L, 591L, 6607935L, 954L, 6295L, 75514344L, 5742050L,
25647276L, 449L, 328566184L, 4L, 2L, 2703L, 21367543L, 63429043L,
708L, 782L, 909820L, 478L, 50L, 922L, 579882L, 7850L, 534L, 2157492L,
96L, 6L, 716L, 5L, 653290336L, 447854237L, 2L, 31972263L, 645L,
7L, 609909L, 4054695L, 455631L, 4919894L, 9L, 72713L, 9997L,
84090765L, 89742L, 5L, 5028L, 4126L, 23091L, 81L, 239635020L,
3576L, 898597785L, 6822L, 3798L, 201999L, 19624L, 20432923L,
18944093L, 930720236L, 1492302L, 300122L, 143633L, 5152743L,
417344L, 813L, 55792L, 78L), Center_Freq = c(61907L, 8709547L,
300750537L, 45862L, 91417085L, 79892L, 47765L, 5477L, 18L, 4186L,
2860L, 754038591L, 375L, 53809223L, 72L, 136L, 4700783L, 4173830L,
30L, 811L, 341014L, 780L, 44749L, 91L, 201620707L, 74L, 1L, 65422L,
595L, 89093186L, 946520L, 6940919L, 48744L, 2317845L, 5126197L,
2445L, 8L, 557450L, 450259742L, 21006647L, 9L, 7234027L, 59L,
9L, 651547554L, 45554L, 38493L, 91055218L, 38L, 1116474L, 2295482L,
3001L, 9L, 3270L, 141L, 53644L, 667983L, 565598L, 84L, 971L,
555498297L, 60431L, 6597L, 856943893L, 607815536L, 4406L, 79L,
4885076L, 745L, 8L, 56456L, 125140L, 73043989L, 516476L, 7L,
4440739L, 754038591L, 375L, 53809223L, 72L, 136L, 509L, 232325L,
13128104L, 1692L, 8581L, 23L, 5874213L, 4550L, 644668065L, 3712371L,
5928L, 8833L, 7L, 2186023L, 61627221L, 37297L, 716427989L, 21387L
), Start.Freq = c(426355L, 22073538L, 680374L, 41771L, 54L, 6762844L,
599171L, 108L, 257451851L, 438814L, 343045L, 4702L, 967787L,
1937L, 18L, 89301735L, 366L, 90L, 954L, 7337732L, 70891703L,
4139L, 10397931L, 940000382L, 7L, 38376L, 878528819L, 6287L,
738366L, 31L, 47L, 5L, 6L, 77848L, 2366508L, 45L, 3665842L, 7252260L,
6L, 61L, 3247L, 448348L, 1L, 705132L, 144L, 7423637L, 2L, 497L,
844927639L, 78978L, 914L, 131L, 7089563L, 927L, 9595581L, 2774463L,
1651L, 73509280L, 7L, 35L, 18L, 96L, 1L, 92545512L, 27354947L,
7556L, 65019L, 7480L, 71835L, 8249L, 64792L, 71537L, 349389666L,
280244484L, 82L, 6L, 40L, 353872L, 0L, 103L, 1255L, 4752L, 29L,
76L, 81185L, 14L, 9L, 470775630L, 818361265L, 57947209L, 44L,
24L, 41295L, 4L, 261449L, 9931404L, 773556640L, 930717L, 65007421L
), End.Freq = c(71000996L, 11613579L, 71377155L, 1942738L, 8760748L,
79L, 455L, 374L, 8L, 5L, 2266932L, 597833L, 155488L, 3020L, 4L,
554L, 4L, 16472L, 1945649L, 668181101L, 649780L, 22394365L, 93060602L,
172146L, 20472L, 23558847L, 190513L, 22759044L, 44L, 78450L,
205621181L, 218L, 69916344L, 23884L, 66L, 312148L, 7710564L,
4L, 422L, 744572L, 651547554L, 45554L, 38493L, 91055218L, 38L,
1116474L, 2295482L, 3001L, 9L, 3270L, 141L, 55595L, 38451L, 8660867L,
14L, 96L, 345L, 6L, 44L, 8235824L, 910517L, 1424326L, 87102566L,
53644L, 667983L, 565598L, 84L, 971L, 555498297L, 60431L, 6597L,
856943893L, 607815536L, 4406L, 79L, 7L, 28978746L, 7537295L,
6L, 633L, 345860066L, 802L, 1035131L, 602L, 2740L, 8065L, 61370968L,
429953765L, 981507L, 8105L, 343787257L, 44782L, 64184L, 12981359L,
123367978L, 818775L, 123745614L, 25345654L, 3L), Country = c("Holland",
"Holland", "Holland", "Holland", "Holland", "Holland", "Spain",
"Spain", "Spain", "Spain", "Spain", "Spain", "Spain", "Spain",
"Spain", "Spain", "Spain", "Spain", "Holland", "Holland", "Holland",
"Holland", "Holland", "Holland", "France", "France", "France",
"France", "France", "France", "France", "France", "France", "France",
"France", "Spain", "Spain", "Spain", "Spain", "Spain", "Spain",
"Spain", "Spain", "France", "France", "France", "France", "Holland",
"Holland", "Holland", "Holland", "Holland", "Holland", "Holland",
"Holland", "Holland", "Holland", "Holland", "Holland", "Holland",
"Spain", "Spain", "Spain", "Spain", "Spain", "Spain", "Spain",
"Holland", "Holland", "Holland", "Holland", "France", "France",
"France", "France", "France", "France", "France", "Spain", "Spain",
"Spain", "Spain", "Spain", "Spain", "Spain", "Spain", "Spain",
"Spain", "Spain", "Spain", "Spain", "Spain", "Spain", "Spain",
"Spain", "Spain", "France", "France", "France")), row.names = c(NA,
99L), class = "data.frame")
CodePudding user response:
Thanks for including all the required information; I believe this is the solution to your problem:
library(magrittr)
library(gbm)
#> Loaded gbm 2.1.8
library(caret)
#> Loading required package: ggplot2
#> Loading required package: lattice
library(e1071)
set.seed(45L)
# Load in your example data to an object ("data")
#Produce a new version of the data frame 'Clusters_Dummy' with the rows shuffled
Cluster_Dummy_2 <- data
NewClusters <- Cluster_Dummy_2[sample(1:nrow(Cluster_Dummy_2)),]
NewCluster<-as.data.frame(NewClusters)
training.parameters <- Cluster_Dummy_2$Country %>%
createDataPartition(p = 0.7, list = FALSE)
train.data <- NewClusters[training.parameters, ]
test.data <- NewClusters[-training.parameters, ]
dim(train.data)
#> [1] 70 11
#259 10
dim(test.data)
#> [1] 29 11
#108 10
#Auxiliary function for controlling model fitting
#10 fold cross validation; 10 times
fitControl <- trainControl(## 10-fold CV
method = "repeatedcv",
number = 10,
## repeated ten times
repeats = 10,
classProbs = TRUE)
#Fit the model
gbmFit1 <- train(Country ~ ., data=train.data,
method = "gbm",
trControl = fitControl,
## This last option is actually one
## for gbm() that passes through
verbose = FALSE)
gbmFit1
#> Stochastic Gradient Boosting
#>
#> 70 samples
#> 10 predictors
#> 2 classes: 'France', 'Holland'
#>
#> No pre-processing
#> Resampling: Cross-Validated (10 fold, repeated 10 times)
#> Summary of sample sizes: 64, 64, 63, 63, 63, 62, ...
#> Resampling results across tuning parameters:
#>
#> interaction.depth n.trees Accuracy Kappa
#> 1 50 0.7397619 0.4810245
#> 1 100 0.7916667 0.5816756
#> 1 150 0.8204167 0.6392434
#> 2 50 0.7396429 0.4813670
#> 2 100 0.7943452 0.5901254
#> 2 150 0.8380357 0.6768166
#> 3 50 0.7361905 0.4711780
#> 3 100 0.7966071 0.5897921
#> 3 150 0.8356548 0.6694202
#>
#> Tuning parameter 'shrinkage' was held constant at a value of 0.1
#>
#> Tuning parameter 'n.minobsinnode' was held constant at a value of 10
#> Accuracy was used to select the optimal model using the largest value.
#> The final values used for the model were n.trees = 150, interaction.depth =
#> 2, shrinkage = 0.1 and n.minobsinnode = 10.
summary(gbmFit1)
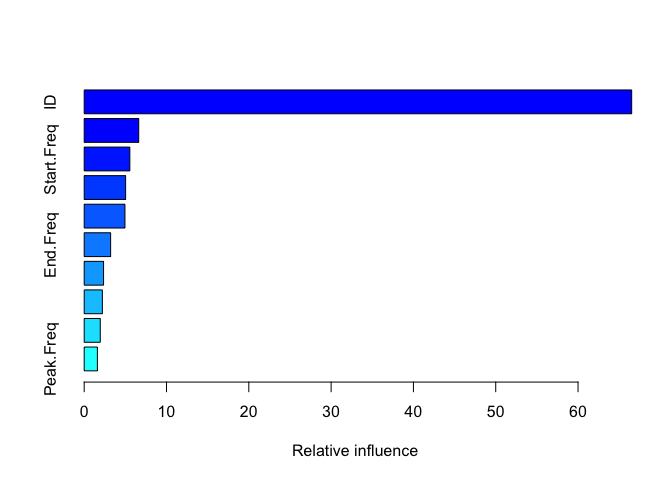
#> var rel.inf
#> ID ID 66.517974
#> Center_Freq Center_Freq 6.624256
#> Start.Freq Start.Freq 5.545827
#> Delta.Time Delta.Time 5.033223
#> Peak.Time Peak.Time 4.951384
#> End.Freq End.Freq 3.211461
#> Delta.Freq Delta.Freq 2.352933
#> Low.Freq Low.Freq 2.207371
#> High.Freq High.Freq 1.951895
#> Peak.Freq Peak.Freq 1.603675
#Predict the model with the test data
pred_model_Tree1 <- predict(object = gbmFit1, newdata = test.data, type = "prob")
pred_model_Tree1
#> France Holland
#> 1 0.919393487 0.080606513
#> 2 0.095638010 0.904361990
#> 3 0.019038102 0.980961898
#> 4 0.045807668 0.954192332
#> 5 0.157809127 0.842190873
#> 6 0.987391435 0.012608565
#> 7 0.011436393 0.988563607
#> 8 0.032262438 0.967737562
#> 9 0.151393564 0.848606436
#> 10 0.993447390 0.006552610
#> 11 0.020833439 0.979166561
#> 12 0.993910239 0.006089761
#> 13 0.009170816 0.990829184
#> 14 0.010519644 0.989480356
#> 15 0.995338954 0.004661046
#> 16 0.994153479 0.005846521
#> 17 0.998099611 0.001900389
#> 18 0.056571139 0.943428861
#> 19 0.801327096 0.198672904
#> 20 0.192220458 0.807779542
#> 21 0.899189477 0.100810523
#> 22 0.766542297 0.233457703
#> 23 0.940046468 0.059953532
#> 24 0.069087397 0.930912603
#> 25 0.916674076 0.083325924
#> 26 0.023676968 0.976323032
#> 27 0.996824979 0.003175021
#> 28 0.996068088 0.003931912
#> 29 0.096807861 0.903192139
# Evaluate each prediction, i.e. if the predicted likelihood that the country is France is '0.9'
# and the likelihood it's Holland is '0.1', then the prediction is "France"
pred_model_Tree1$evaluation <- ifelse(pred_model_Tree1$France >= 0.5, "France", "Holland")
# Now you can print the confusionMatrix (make sure each factor has the same levels)
confusionMatrix(factor(pred_model_Tree1$evaluation, levels = unique(test.data$Country)),
factor(test.data$Country, levels = unique(test.data$Country)))
#> Confusion Matrix and Statistics
#>
#> Reference
#> Prediction France Holland
#> France 13 1
#> Holland 0 15
#>
#> Accuracy : 0.9655
#> 95% CI : (0.8224, 0.9991)
#> No Information Rate : 0.5517
#> P-Value [Acc > NIR] : 7.947e-07
#>
#> Kappa : 0.9308
#>
#> Mcnemar's Test P-Value : 1
#>
#> Sensitivity : 1.0000
#> Specificity : 0.9375
#> Pos Pred Value : 0.9286
#> Neg Pred Value : 1.0000
#> Prevalence : 0.4483
#> Detection Rate : 0.4483
#> Detection Prevalence : 0.4828
#> Balanced Accuracy : 0.9688
#>
#> 'Positive' Class : France
#>
Created on 2022-06-02 by the reprex package (v2.0.1)
Edit
Something seems wrong - perhaps you want to remove the IDs before you train/test the model? (Maybe they weren't randomly assigned?) E.g.
library(dplyr)
#>
#> Attaching package: 'dplyr'
#> The following objects are masked from 'package:stats':
#>
#> filter, lag
#> The following objects are masked from 'package:base':
#>
#> intersect, setdiff, setequal, union
library(gbm)
#> Loaded gbm 2.1.8
library(caret)
#> Loading required package: ggplot2
#> Loading required package: lattice
library(e1071)
set.seed(45L)
#Produce a new version of the data frame 'Clusters_Dummy' with the rows shuffled
Cluster_Dummy_2 <- data
NewClusters <- Cluster_Dummy_2[sample(1:nrow(Cluster_Dummy_2)),]
NewCluster<-as.data.frame(NewClusters)
training.parameters <- Cluster_Dummy_2$Country %>%
createDataPartition(p = 0.7, list = FALSE)
train.data <- NewClusters[training.parameters, ] %>%
select(-ID)
test.data <- NewClusters[-training.parameters, ] %>%
select(-ID)
dim(train.data)
#> [1] 70 10
dim(test.data)
#> [1] 29 10
#Auxiliary function for controlling model fitting
#10 fold cross validation; 10 times
fitControl <- trainControl(## 10-fold CV
method = "repeatedcv",
number = 10,
## repeated ten times
repeats = 10,
classProbs = TRUE)
#Fit the model
gbmFit1 <- train(Country ~ ., data=train.data,
method = "gbm",
trControl = fitControl,
## This last option is actually one
## for gbm() that passes through
verbose = FALSE)
gbmFit1
#> Stochastic Gradient Boosting
#>
#> 70 samples
#> 9 predictor
#> 2 classes: 'France', 'Holland'
#>
#> No pre-processing
#> Resampling: Cross-Validated (10 fold, repeated 10 times)
#> Summary of sample sizes: 64, 64, 63, 63, 63, 62, ...
#> Resampling results across tuning parameters:
#>
#> interaction.depth n.trees Accuracy Kappa
#> 1 50 0.5515476 0.08773090
#> 1 100 0.5908929 0.17272118
#> 1 150 0.5958333 0.18280502
#> 2 50 0.5386905 0.06596478
#> 2 100 0.5767262 0.13757567
#> 2 150 0.5785119 0.14935661
#> 3 50 0.5575000 0.09991455
#> 3 100 0.5585119 0.10906906
#> 3 150 0.5780952 0.14820067
#>
#> Tuning parameter 'shrinkage' was held constant at a value of 0.1
#>
#> Tuning parameter 'n.minobsinnode' was held constant at a value of 10
#> Accuracy was used to select the optimal model using the largest value.
#> The final values used for the model were n.trees = 150, interaction.depth =
#> 1, shrinkage = 0.1 and n.minobsinnode = 10.
summary(gbmFit1)
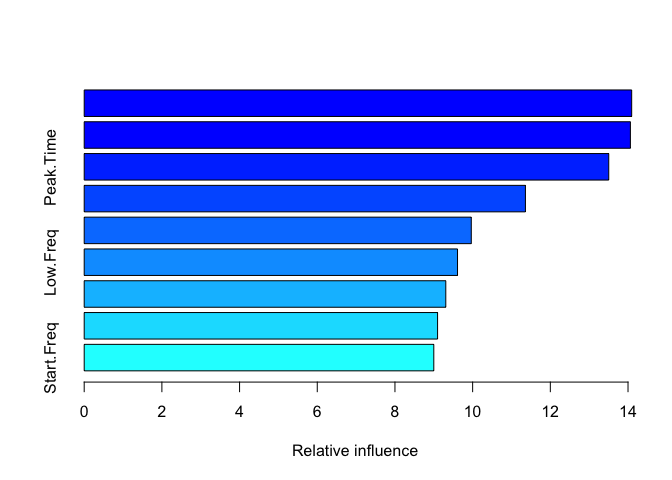
#> var rel.inf
#> Center_Freq Center_Freq 14.094306
#> High.Freq High.Freq 14.060959
#> Peak.Time Peak.Time 13.503953
#> Peak.Freq Peak.Freq 11.358891
#> Delta.Time Delta.Time 9.964882
#> Low.Freq Low.Freq 9.610686
#> End.Freq End.Freq 9.308919
#> Delta.Freq Delta.Freq 9.097253
#> Start.Freq Start.Freq 9.000152
#Predict the model with the test data
pred_model_Tree1 <- predict(object = gbmFit1, newdata = test.data, type = "prob")
pred_model_Tree1
#> France Holland
#> 1 0.75514031 0.24485969
#> 2 0.44409692 0.55590308
#> 3 0.15027904 0.84972096
#> 4 0.49861536 0.50138464
#> 5 0.95406713 0.04593287
#> 6 0.82122854 0.17877146
#> 7 0.27931450 0.72068550
#> 8 0.50113421 0.49886579
#> 9 0.61912973 0.38087027
#> 10 0.91005442 0.08994558
#> 11 0.42625105 0.57374895
#> 12 0.27339404 0.72660596
#> 13 0.14520192 0.85479808
#> 14 0.16607144 0.83392856
#> 15 0.97198722 0.02801278
#> 16 0.88614818 0.11385182
#> 17 0.65561219 0.34438781
#> 18 0.86793709 0.13206291
#> 19 0.28583233 0.71416767
#> 20 0.97002073 0.02997927
#> 21 0.74408374 0.25591626
#> 22 0.28408111 0.71591889
#> 23 0.07257257 0.92742743
#> 24 0.22724577 0.77275423
#> 25 0.32581206 0.67418794
#> 26 0.59713799 0.40286201
#> 27 0.75814205 0.24185795
#> 28 0.94018097 0.05981903
#> 29 0.51155700 0.48844300
# Evaluate each prediction, i.e. if the predicted likelihood that the country is France is '0.9'
# and the likelihood it's Holland is '0.1', then the prediction is "France"
pred_model_Tree1$evaluation <- ifelse(pred_model_Tree1$France >= 0.5, "France", "Holland")
# Now you can print the confusionMatrix (make sure each factor has the same levels)
confusionMatrix(factor(pred_model_Tree1$evaluation, levels = unique(test.data$Country)),
factor(test.data$Country, levels = unique(test.data$Country)))
#> Confusion Matrix and Statistics
#>
#> Reference
#> Prediction France Holland
#> France 9 7
#> Holland 4 9
#>
#> Accuracy : 0.6207
#> 95% CI : (0.4226, 0.7931)
#> No Information Rate : 0.5517
#> P-Value [Acc > NIR] : 0.2897
#>
#> Kappa : 0.2494
#>
#> Mcnemar's Test P-Value : 0.5465
#>
#> Sensitivity : 0.6923
#> Specificity : 0.5625
#> Pos Pred Value : 0.5625
#> Neg Pred Value : 0.6923
#> Prevalence : 0.4483
#> Detection Rate : 0.3103
#> Detection Prevalence : 0.5517
#> Balanced Accuracy : 0.6274
#>
#> 'Positive' Class : France
#>
Created on 2022-06-02 by the reprex package (v2.0.1)