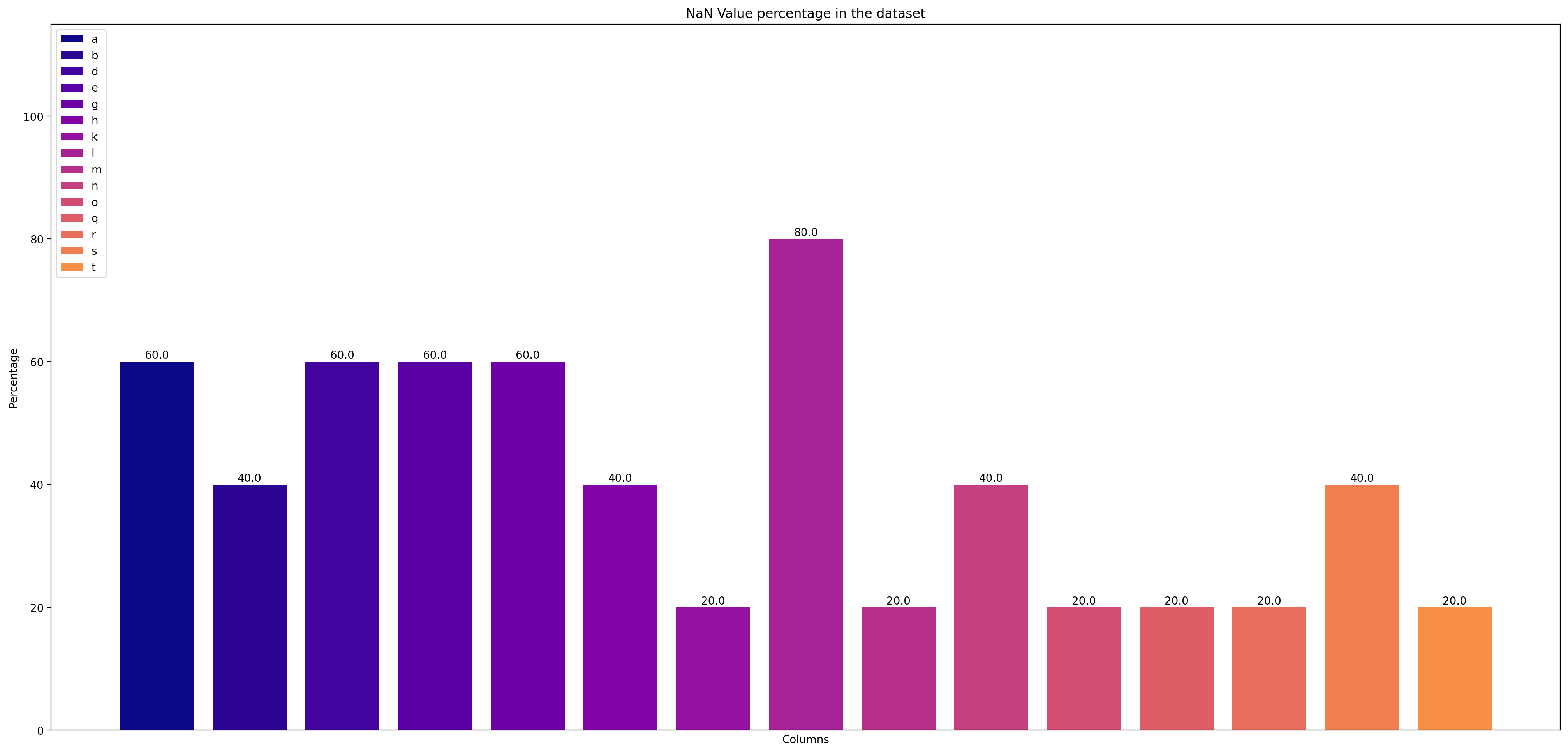
I calculated NaN value percentage of a dataframe and then plotted it. I want each variable to have a unique color. The code I used works well but every 9th variable color is same as 1st variable color, and the cycle repeats. See the pic:
The code:
per = df.isna().mean().round(4) * 100
f, ax = plt.subplots(figsize=(25, 12), dpi = 200)
i = 0
for key, value in zip(per.keys(), per.values):
if (value > 0):
ax.bar(key, value, label=key)
ax.text(i, value 0.5, str(np.round(value, 2)), ha='center')
i = i 1
ax.set_xticklabels([])
ax.set_xticks([])
plt.title('NaN Value percentage in the dataset')
plt.ylim(0,115)
plt.ylabel('Percentage')
plt.xlabel('Columns')
plt.legend(loc='upper left')
plt.show()
I tried the following line of code, but it picked only first color:
my_colors = list(islice(cycle(['b', 'r', 'g', 'y', 'c', 'm',
'tan', 'grey', 'pink', 'chocolate', 'gold']), None, len(df)))
f, ax = plt.subplots(figsize=(25, 12), dpi = 200)
i = 0
for key, value in zip(per.keys(), per.values):
if (value > 0):
ax.bar(key, value, label=key, color = my_colors)
ax.text(i, value 0.5, str(np.round(value, 2)), ha='center')
i = i 1
ax.set_xticklabels([])
ax.set_xticks([])
plt.title('NaN Value percentage in the dataset')
plt.ylim(0,115)
plt.ylabel('Percentage')
plt.xlabel('Columns')
plt.legend(loc='upper left')
plt.show()
The result:
Any help is appreciated.
See the data 
Or non-random (comment out random.shuffle(lst)):