Hello everyone this is my first question here. I have been browsing thru the questions but couldnt quite find the answer to my problem:
I have a couple of tables which I need to join. The key I join with is non unique(in this case its a date). This is working fine but now I also need to group the results based on another column without getting cross-join like results (meaning each value of this column should only appear once but depending on the table used the column can have different values in each table)
Here is an example of what I have and what I would like to get:
Table1
| Date/Key | Group Column | Example Value1 |
|---|---|---|
| 01-01-2022 | a | 1 |
| 01-01-2022 | d | 2 |
| 01-01-2022 | e | 3 |
| 01-01-2022 | f | 4 |
Table 2
| Date/Key | Group Column | Example Value 2 |
|---|---|---|
| 01-01-2022 | a | 1 |
| 01-01-2022 | b | 2 |
| 01-01-2022 | c | 3 |
| 01-01-2022 | d | 4 |
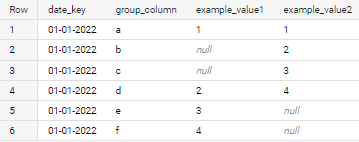
Wanted Result :
Table Result
| Date/Key | Group Column | Example Value1 | Example Value2 |
|---|---|---|---|
| 01-01-2022 | a | 1 | 1 |
| 01-01-2022 | b | NULL | 2 |
| 01-01-2022 | c | NULL | 3 |
| 01-01-2022 | d | 2 | 4 |
| 01-01-2022 | e | 3 | NULL |
| 01-01-2022 | f | 4 | NULL |
I have tryed a couple of approaches but I always get results with values in group column appear multiple times. I am under the impression that full joining and then grouping over the group column shoul work but apparently I am missing something. I also figured I could bruteforce the result by left joining everything with setting the on to table1.date = table2.date AND table1.Groupcolumn = table2.Groupcolumn ect.. and then doing UNIONs of all permutations (so each table was on "the left" once) but this is not only tedious but bigquery doesnt like it since it contains too many sub queries.
I feel kinda bad that my first question is something that I should actually know but I hope someone can help me out!
- I do not need a full code solution just a hint to the correct approach would suffice (also incase I missed it: if this was already answered I also appreciate just a link to it!)
Edit: So one solution I came up with, which appears to work, was to select the group column of each table and union them as a with() and then join this "list" onto the first table like
list as(Select t1.GroupColumn FROM Table_1 t1 WHERE CONDITION1
UNION DISTINCT Select t1.GroupColumn FROM Table_1 t1 WHERE CONDITION2 ... ect)
result as (
SELECT l.GoupColumn, t1.Example_Value1, t2.Example_Value2
FROM Table_1 t1
LEFT JOIN( SELECT * FROM list) s
ON S.GroupColumn = t1.GroupColumn
LEFT JOIN Table_2 t2
on S.GroupColumn = t2.GroupColumn
and t1.key = t2.key
...
)
SELECT * FROM result
CodePudding user response:
I think what you are looking for is a FULL OUTER JOIN and then you can coalesce the date and group columns. It doesn't exactly look like you need to group anything based on the example data you posted:
SELECT
coalesce(table1.date_key, table2.date_key) AS date_key,
coalesce(table1.group_column, table2.group_column) AS group_column,
table1.example_value_1,
table2.example_value_2
FROM
table1
FULL OUTER JOIN
table2
USING
(date_key,
group_column)
ORDER BY
date_key,
group_column;
CodePudding user response:
Consider below simple approach
select * from (
select *, 'example_value1' type from table1 union all
select *, 'example_value2' type from table2
)
pivot (
any_value(example_value1)
for type in ('example_value1', 'example_value2')
)
if applied to sample data in your question - output is